架构概述¶
本文档概述了 vLLM-Omni 的架构设计。
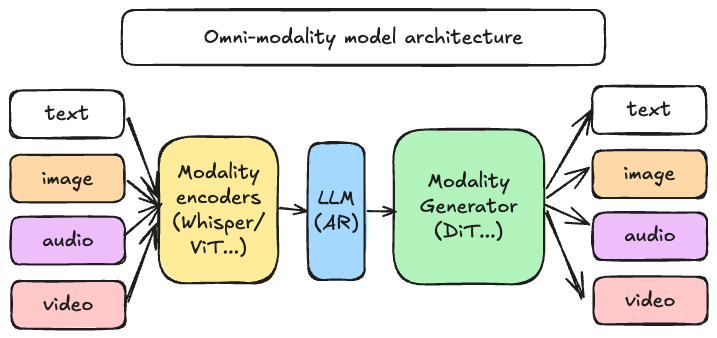
目标¶
vLLM-Omni 项目的主要目标是构建最快速、最易于使用的开源全模态(Omni-Modality)模型推理和 serving 引擎。vLLM-Omni 扩展了最初为支持文本生成任务的自回归(AR)大型语言模型而创建的 vLLM。vLLM-Omni 的设计旨在支持:
- 非文本输出: 支持包括图像、音频和视频等各种数据类型与文本一起集成、高效处理和输出。
- 非自回归结构: 支持除自回归以外的模型结构,特别是广泛用于视觉和音频生成的 Diffusion Transformer (DiT)。
- 与 vLLM 核心集成: 保持兼容性,并在适用时利用现有的 vLLM 关键模块和优化。
- 可扩展性: 设计模块化、灵活的架构,以便轻松适应新的模态、模型架构和输出格式。
代表性的全模态模型¶
根据对当前流行开源模型的分析,大多数模型都结合了 AR+DiT。具体来说,它们可以进一步分为以下 3 种类型:
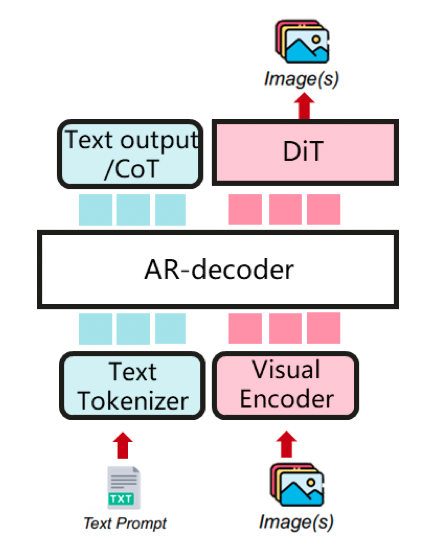
以 DiT 为主结构,以 AR 为文本编码器(例如:Qwen-Image) 一个强大的图像生成基础模型,能够进行复杂的文本渲染和精确的图像编辑。
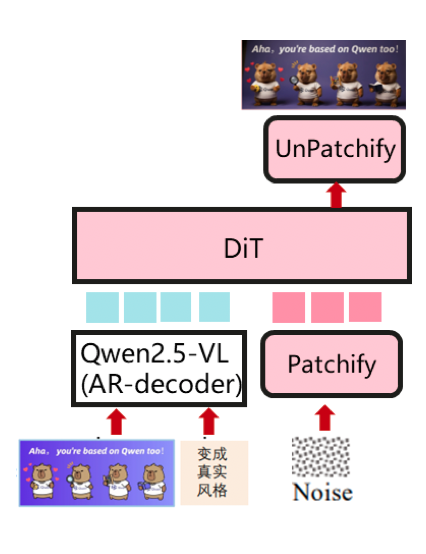
以 AR 为主结构,以 DiT 为多模态生成器(例如:BAGEL) 一个统一的多模态理解和生成模型,可以同时输出文本和视觉内容。
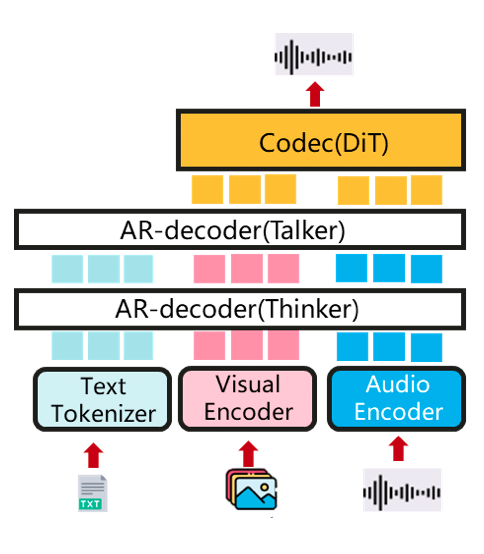
AR+DiT(例如:Qwen-Omni) 一个原生端到端的全模态 LLM,支持多模态输入(文本/图像/音频/视频...)和输出(文本/音频...)。
vLLM-Omni 主要架构¶
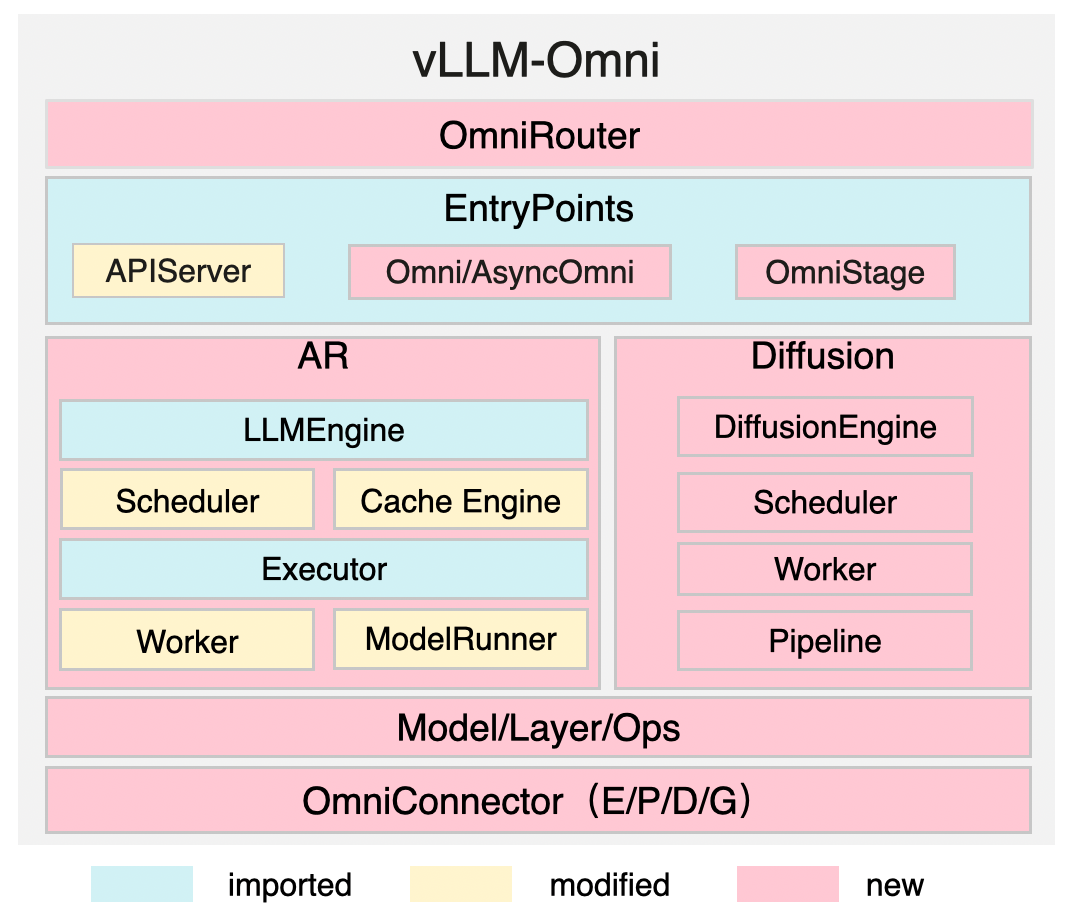
关键组件¶
| 组件 | 描述 |
|---|---|
| OmniRouter | 提供一个智能路由器,用于全模态请求的分派。 |
| EntryPoints | 定义离线/在线 serving 的 API(APIServer、Omni/AsyncOmni),并为不同的 AR/DiT 阶段提供 OmniStage 抽象。 |
| AR | 适配全模态模型,同时继承 vLLM 的高效特性,例如缓存管理。 |
| Diffusion | 原生实现,并使用加速组件进行优化。 |
| OmniConnector | 支持在各个阶段之间实现基于 E/P/D/G(编码/处理/解码/生成)的完全解耦。 |
解耦的阶段通过配置进行管理,例如在 Qwen3-Omni 示例中,Thinker、Talker 和 Code2wav 等阶段被定义为独立的 OmniStage 实例,并具有特定的资源和输入/输出类型。
主要特性¶
vLLM-Omni 旨在通过以下特性实现快速、灵活和易于使用的目标:
性能与加速¶
该框架通过多种优化技术实现高性能:
- 高效的 AR 支持: 利用从 vLLM 继承的高效 KV 缓存管理。
- 流水线执行: 使用流水线阶段执行重叠,以确保高吞吐量。
- 完全解耦: 依赖 OmniConnector 和跨阶段的动态资源分配。
- 扩散加速: 集成了对扩散加速的支持。这由加速层管理,该层负责:
- 缓存: 包括 DBCache、TeaCache 和第三方集成(例如:cache-dit)。
- 并行: 支持 TP、CP、USP 和 CFG。
- 注意力: 提供第三方集成的接口(例如:FA3、SAGE、MindIE-SD)。
- 量化: 支持各种量化实现,包括 FP8 和 AWQ。
- 融合操作: 支持自定义和第三方集成。
灵活性与可用性¶
vLLM-Omni 的设计旨在为用户提供灵活性和简洁性:
- 异构流水线抽象: 有效管理复杂的模型工作流。
- Hugging Face 集成: 提供与流行的 Hugging Face 模型无缝集成。
- 分布式推理: 支持张量、流水线、数据和专家并行。
- 流式输出: 支持流式输出。
- 统一 API: 提供与 vLLM 兼容的统一 API 接口。
- OpenAI 兼容 API 服务器: 包括一个基于 FastAPI 的在线 serving 服务器,与 OpenAI API 兼容。
接口设计¶
如果您使用过 vLLM,那么您将能够立即上手使用 vLLM-Omni。
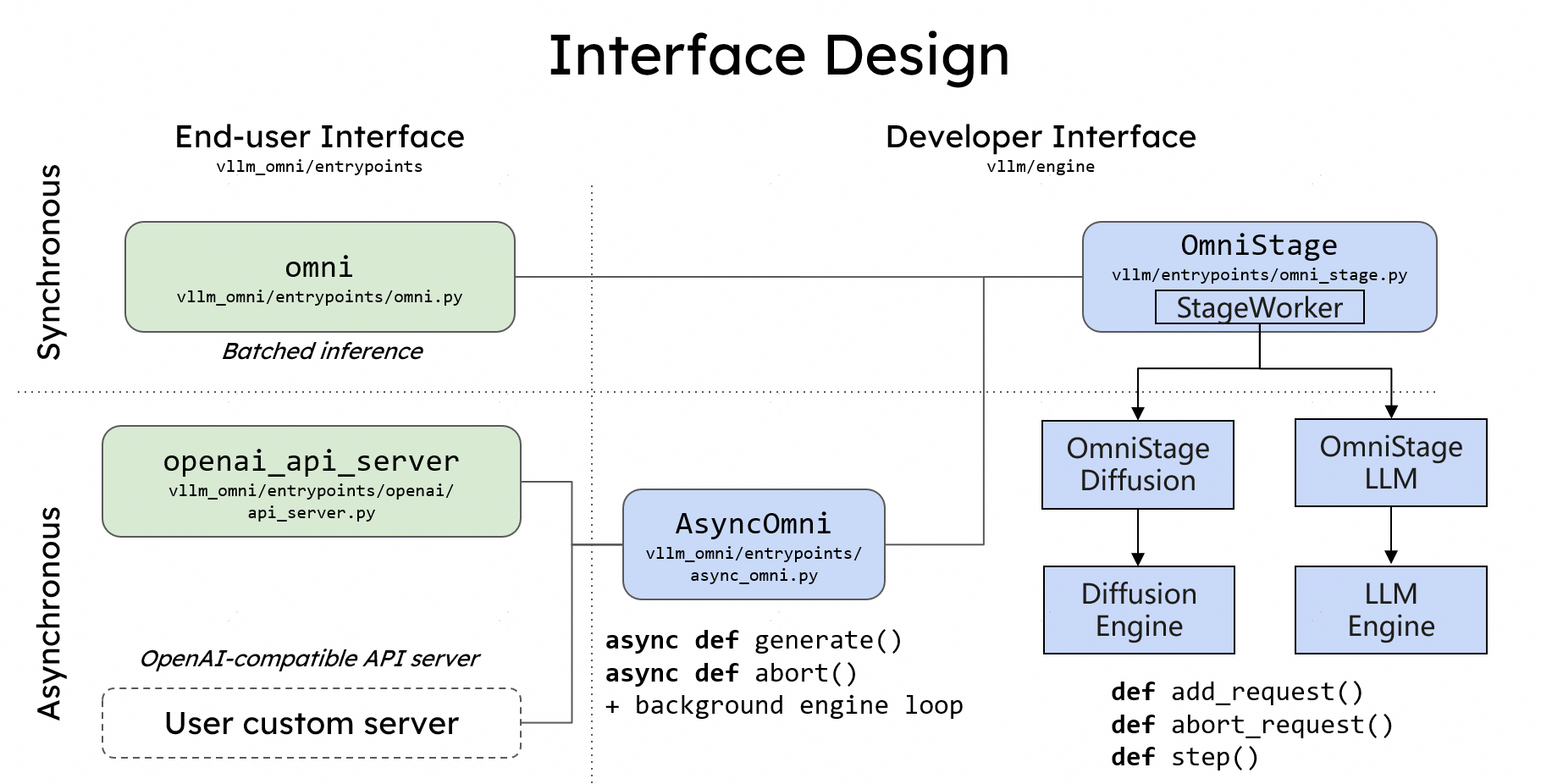
以 **Qwen3-Omni** 为例:
离线推理¶
Omni 类提供了一个用于离线批量推理的 Python 接口。用户使用 Hugging Face 模型名称初始化 Omni 类,并使用 `generate` 方法,传递包含文本提示和多模态数据的输入。
# Create an omni_lm with HF model name.
from vllm_omni.entrypoints.omni import Omni
omni_lm = Omni(model="Qwen/Qwen3-Omni-30B-A3B-Instruct")
# Example prompts.
om_inputs = {"prompt": prompt,
"multi_modal_data": {
"video": video_frames,
"audio": audio_signal,
}}
# Generate texts and audio from the multi-modality inputs.
outputs = omni_lm.generate(om_inputs, sampling_params_list)
在线服务¶
与 vLLM 类似,vLLM-Omni 还提供了一个基于 FastAPI 的在线 serving 服务器。用户可以使用 `vllm serve` 命令并加上 `--omni` 标志来启动服务器。
用户可以使用 curl 向服务器发送请求。
# prepare user content
user_content='[
{
"type": "video_url",
"video_url": {
"url": "'"$SAMPLE_VIDEO_URL"'"
}
},
{
"type": "text",
"text": "Why is this video funny?"
}
]'
sampling_params_list='[
'"$thinker_sampling_params"',
'"$talker_sampling_params"',
'"$code2wav_sampling_params"'
]'
mm_processor_kwargs="{}"
# send the request
curl -sS -X POST https://:8091/v1/chat/completions \
-H "Content-Type: application/json" \
-d @- <<EOF
{
"model": "Qwen/Qwen3-Omni-30B-A3B-Instruct",
"sampling_params_list": $sampling_params_list,
"mm_processor_kwargs": $mm_processor_kwargs,
"messages": [
{
"role": "system",
"content": [
{
"type": "text",
"text": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech."
}
]
},
{
"role": "user",
"content": $user_content
}
]
}
更多用法,请参阅 示例。