分桶机制¶
Intel® Gaudi® 加速器在处理具有固定张量形状的模型时性能最佳。Intel® Gaudi® 图编译器会生成优化的二进制代码,在 Intel® Gaudi® 上实现给定的模型拓扑。在其默认配置下,生成的二进制代码可能高度依赖于输入和输出张量形状,当遇到同一拓扑内具有不同形状的张量时,需要重新编译图。虽然这些二进制文件能够高效利用 Intel® Gaudi®,但编译过程本身可能会在端到端执行中引入明显的开销。在动态推理服务场景中,最小化图编译次数并降低服务器运行时发生图编译的风险非常重要。目前,这通过在三个维度上“分桶”模型的正向传播来实现。
分桶可以显著减少所需图的数量,但它不处理图编译或设备代码生成。这些任务在预热和 HPU 图捕获阶段执行。
分桶策略¶
分桶关注三个维度
batch size:每个批次的样本数量。query length:不包含上下文 token 的序列长度。num blocks:以 block 为单位计算的上下文长度。
分桶范围是基于 4 个参数生成的 - min、step、max 和 limit - 分别应用于 prompt 和 decode 阶段,以及 batch size、query length 和 context block 维度。这些参数会被记录并在 vLLM 启动期间观察到。
INFO 07-07 19:27:37 [exponential.py:36] Prompt bucket config (min, step, max_warmup, limit) bs:[1, 1, 1, 1], seq:[128, 128, 1024, 11]
INFO 07-07 19:27:37 [common.py:85] Generated 36 prompt buckets [bs, query, num_blocks]: [(1, 128, 0), (1, 128, 1), (1, 128, 2), (1, 128, 3), (1, 128, 4), (1, 128, 5), (1, 128, 6), (1, 128, 7), (1, 256, 0), (1, 256, 1), (1, 256, 2), (1, 256, 3), (1, 256, 4), (1, 256, 5), (1, 256, 6), (1, 384, 0), (1, 384, 1), (1, 384, 2), (1, 384, 3), (1, 384, 4), (1, 384, 5), (1, 512, 0), (1, 512, 1), (1, 512, 2), (1, 512, 3), (1, 512, 4), (1, 640, 0), (1, 640, 1), (1, 640, 2), (1, 640, 3), (1, 768, 0), (1, 768, 1), (1, 768, 2), (1, 896, 0), (1, 896, 1), (1, 1024, 0)]
INFO 07-07 19:27:37 [common.py:85] Generated 42 decode buckets [bs, query, num_blocks]: [(1, 1, 128), (1, 1, 256), (1, 1, 384), (1, 1, 512), (1, 1, 640), (1, 1, 768), (1, 1, 896), (1, 1, 1024), (1, 1, 1408), (1, 1, 1792), (1, 1, 2432), (1, 1, 3328), (1, 1, 4352), (1, 1, 5888), (2, 1, 128), (2, 1, 256), (2, 1, 384), (2, 1, 512), (2, 1, 640), (2, 1, 768), (2, 1, 896), (2, 1, 1024), (2, 1, 1408), (2, 1, 1792), (2, 1, 2432), (2, 1, 3328), (2, 1, 4352), (2, 1, 5888), (4, 1, 128), (4, 1, 256), (4, 1, 384), (4, 1, 512), (4, 1, 640), (4, 1, 768), (4, 1, 896), (4, 1, 1024), (4, 1, 1408), (4, 1, 1792), (4, 1, 2432), (4, 1, 3328), (4, 1, 4352), (4, 1, 5888)]
警告
如果一个请求在任何维度上超过最大分桶大小,它将被处理而无需填充,并且其处理可能需要图编译,这可能会显著增加端到端延迟。分桶的边界可以通过环境变量由用户配置,并且可以增加上层分桶边界以避免这种情况。
例如,如果一个包含 3 个序列(每个序列的最大序列长度为 412)的请求被发送到一个空闲的 vLLM 服务器,它将被填充并作为 (4, 512, 0) 的 prefill 分桶处理,其中
- 4 是 batch size,向上填充到大于 3 的最近支持值
- 512 是序列长度,向上填充到大于 412 的最近支持值
在 prefill 阶段之后,它将作为一个 (4, 1, 512) 的 decode 分桶处理,该分桶将保持使用状态,直到
- batch 维度发生变化(例如,当一个请求完成时),此时它将变为
(2, 1, 512)。 - 上下文长度超过 512 个 token,此时它将变为
(4, 1, 640)。
分桶对用户是透明的 - 序列长度维度的填充永远不会被返回,batch 维度的填充也不会创建新请求。
有三种分桶策略:指数(默认)、线性、统一。
指数策略¶
指数策略是默认的预热机制。它基于 4 个用户不可配置的参数
min:最小值step:分桶边界的四舍五入值max:最大值limit:最大分桶数量
指数分桶策略在分桶之间应用指数间隔。min 和 max 值始终包含在预热中,中间值使用指数计算。基数保持不变。如果生成重复值,则会将其删除以确保预热过程尽可能高效。所有以这种方式生成的值,包括 batch size、query length 和 context blocks,都会相互预热。
以下示例展示了一种可能的分布
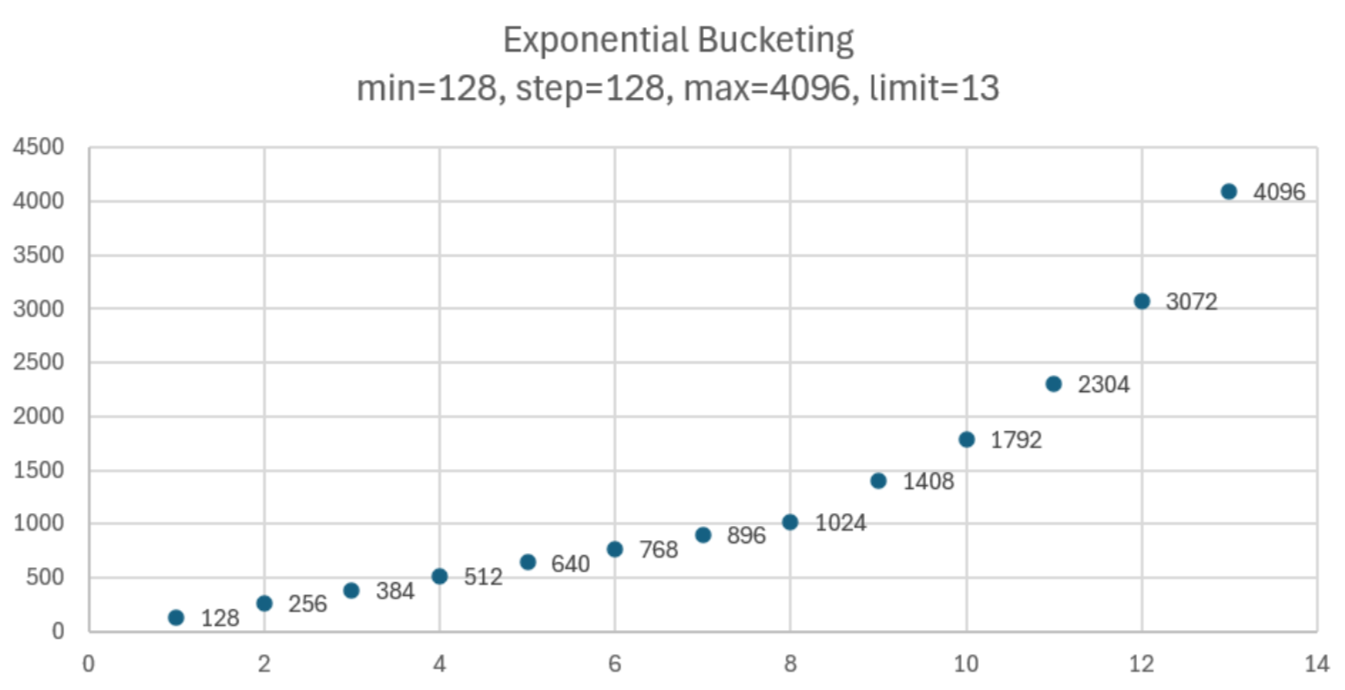
此策略在靠近 min 的地方创建更多具有较小值的分桶。当值向 max 增加时,分桶变得不那么频繁,这意味着它们之间的距离会增加。这有助于更精确地优先预热较小值,同时仍然覆盖整个范围。
线性策略¶
注意
从 v1.22.0 Intel Gaudi 软件版本开始,线性策略不再是默认的预热机制。
线性策略由 3 个参数确定:min、step 和 max,其中
min:分桶的最小值step:分桶之间的间隔max:分桶的最大值
这些参数可以由用户单独为 prompt 和 decode 阶段以及 batch size 和 sequence length 维度进行配置。min 和 step 之间的间隔有特殊处理:min 乘以 2 的连续幂,直到乘数小于或等于 step。我们将此称为 ramp-up(启动)阶段,用于处理较小的 batch size 并最大限度地减少浪费,同时允许在较大的 batch size 上进行较大的填充。
Alpha 版本¶
当前 query length、shared blocks 和 unique blocks 的范围中有六个点。它们基于 max num seqs 和 max num batched tokens 值。这些点设置在两个参数的整个值、一半值和四分之一值处,总共产生六个点。
以下示例展示了一种可能的分布
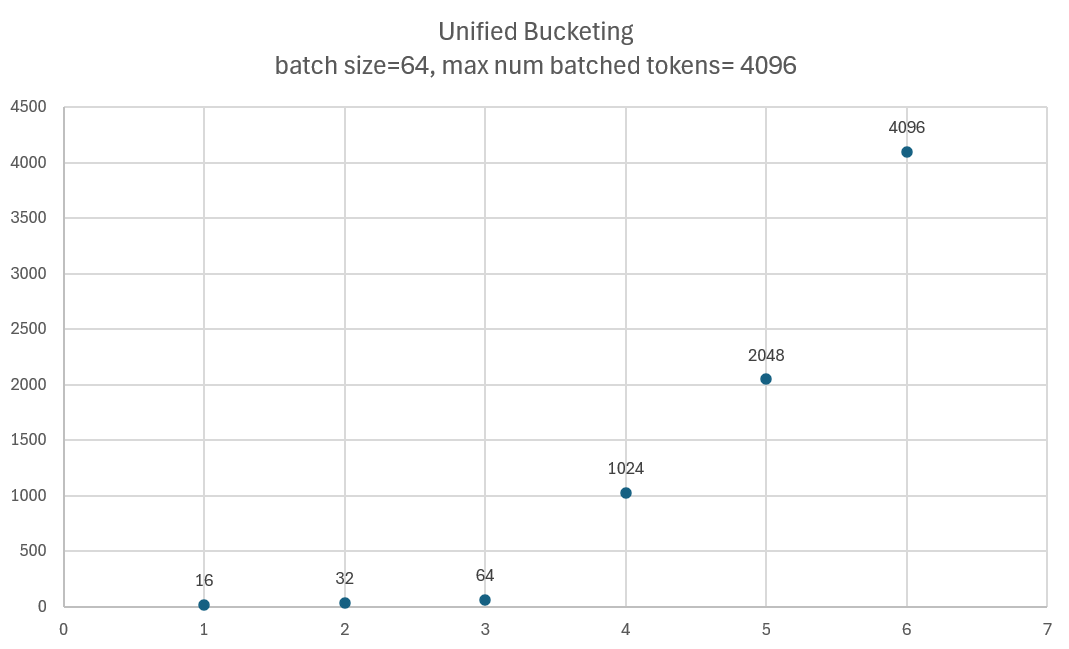
此外,对于 shared 和 unique 的 context blocks,还包含了一个 0 值,从而产生以下分桶
INFO 09-23 12:32:43 [common.py:100] Generated 375 unified buckets [query, shared_blocks, unique_blocks]: [(8, 0, 0, 1), (8, 0, 8, 0), ..., (2048, 256, 2890, 1), (2048, 256, 5781, 1)]
以下示例展示了一个在预热阶段单独记录每个分桶的设置
(EngineCore_DP0 pid=805) INFO 09-23 12:32:50 [hpu_model_runner.py:3320] [Warmup][Unified CFG][2/375] query_len:2048 shared_blocks:256 unique_blocks:2890 (causal) free_mem:11.16 GiB
(EngineCore_DP0 pid=805) INFO 09-23 12:32:53 [hpu_model_runner.py:3320] [Warmup][Unified CFG][3/375] query_len:2048 shared_blocks:256 unique_blocks:1445 (causal) free_mem:11.16 GiB
(EngineCore_DP0 pid=805) INFO 09-23 12:32:56 [hpu_model_runner.py:3320] [Warmup][Unified CFG][4/375] query_len:2048 shared_blocks:256 unique_blocks:32 (causal) free_mem:11.16 GiB
在文件中指定分桶¶
基于文件的分桶允许您通过在配置文件中指定它们来手动配置精确的分桶。要使用此方法,请将 VLLM_BUCKETING_FROM_FILE 标志设置为您的配置文件路径。
您可以使用三种方法在文件中定义分桶。
- 精确分桶:只准备一个特定的分桶。以下示例总共创建了两个分桶:
(1, 2048, 0)和(64, 1, 1024)。
- 列表:从提供的列表元素中通过笛卡尔积准备每个分桶。以下示例创建了六个分桶:
(1, 256, 0)、(1, 256, 4)、(1, 256, 8)、(1, 512, 0)、(1, 512, 4)和(1, 512, 8)。
- 范围:其工作方式类似于列表,但您可以直接设置每个元素,也可以使用 Python 的 range 函数。以下示例创建了三个分桶:
(1, 1, 256)、(1, 1, 384)和(1, 1, 512)。
您可以在同一个文件中混合这三种方法,例如 ([64, 128, 256], 1, range(512, 1024, 32)) 是一个有效的配置。
每个分桶或配置必须单独一行。您可以在 bucketing_file.txt 中找到一个分桶示例。