统一注意力 (Unified Attention)
概述¶
vLLM Intel® Gaudi® 硬件插件 v1.24.0 将引入一种新的注意力后端,称为统一注意力 (Unified Attention),它将几种先前的算法统一到一个实现中。作为一个新添加的后端,它目前支持计划功能的一个子集。与早期方法相比,它提供了以下优点:
- 正确处理使用连续 KV 缓存时共享的块。
- 支持混合批次,使预填充 (prefill) 和解码 (decode) token 可以在单个批次中运行。
- 展平的查询 token 处理,例如,允许在没有单独
seq_len维度的情况下处理所有查询 token。
算法¶
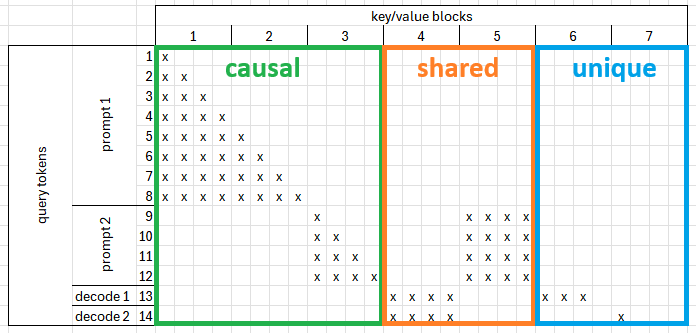
为了理解算法,让我们通过一个具体的例子来逐步讲解。假设有以下设置:
- 块大小:4
- 批次:4 个样本,包含 2 个预填充样本和 2 个解码样本
- 查询长度:[8, 4, 1, 1]
- 上下文长度:[0, 4, 6, 4]
- 注意力机制:缩放点积注意力 (Scaled dot-product attention)

在此示例中,您可以观察到:
- 一些块仅被单个 token 使用,而另一些块被共享。
- 一些最近计算的键值 (key values) 与查询一起可用,无需从缓存中获取。
在一个简单的实现中,我们会将整个查询与键和值相乘,并使用适当的偏置来屏蔽未使用的字段。然而,这种方法效率极低,尤其是在解码时,通常批次中每个样本只有一个 token,并且使用过的块之间几乎没有重叠。
另一种方法是将查询和键切分成块,并仅相乘相关的区域。尽管这种方法目前在技术上实现起来具有挑战性。
相反,我们将计算分为 3 个独立的部分,并在最后合并结果。
拆分 Softmax (Splitting Softmax)¶
统一注意力使用的主要技术是拆分和合并 softmax 值。Softmax 定义为:
问题在于分母,因为它包含所有项的总和。这就是为什么我们将计算拆分为两个单独的 softmax 操作,然后调整和合并结果。假设我们有以下变量:
然后我们可以计算以下内容:
这样,我们就计算了 softmax 的部分,然后重新调整并重新组合值以得到最终结果。我们还可以使用另外两种优化。由于该过程最终涉及除以全局总和,我们可以跳过除以局部总和,然后在重新调整时乘以局部总和,从而在不进行除法的情况下保留中间 softmax 值。此外,由于重新调整涉及乘以一个常数,我们可以使用以下规则:
这使得在注意力计算中将 softmax 重新调整移到乘以 V 之后成为可能。
因果注意力 (Causal Attention)¶
因果注意力用于计算当前计算的 Q、K 和 V 之间的注意力值。由于这些数据最近已计算,因此无需从 KV 缓存中获取。提示长度通常远长于 max_num_seqs。这意味着我们无需区分在提示中使用哪些 token 以及在解码中使用哪些 token,而是依赖于注意力偏置来屏蔽不必要的 token。由于我们顺序使用所有查询 token,因此它的工作方式类似于合并的预填充功能。以下示例展示了计算出的因果偏置可能的样子:

我们可以将查询分成相等的切片,以便每个切片使用不同长度的键:
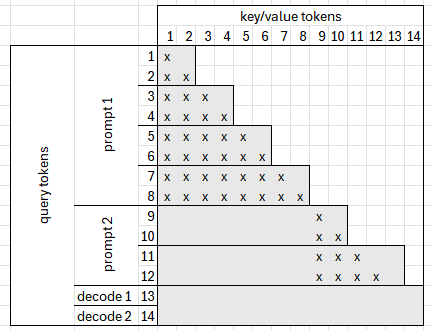
这样,我们可以跳过 index(key) 大于 index(query) 的计算部分。在当前实现中,切片大小是恒定的,并且根据实验结果设置为 512。
共享注意力 (Shared Attention)¶
当多个 token 共享单个上下文块时,使用共享注意力。当存在带有已缓存部分上下文的提示,或在多个样本共享通用前缀的解码期间,通常会发生这种情况。由于共享块被使用多次,因此所有共享块都会被获取并与所有查询 token 相乘。通常,与整个 KV 缓存相比,共享块的数量相对较少,这使得获取它们比依赖于 contiguous_pa 等技巧更好。主要挑战在于创建 shared_bias。
唯一注意力 (Unique Attention)¶
由于我们知道每个块最多被一个 token 使用,我们可以使用两个优化:
- 为每个块而不是每个查询 token 计算注意力。
- 连续的 KV 缓存切片而不是获取单个块。
第一个优化可以更好地处理序列长度差异很大的批次。例如,如果我们批次中有两个样本,分别使用 [4, 12] 个上下文块,而不是将 block_table 填充到最大块数,我们可以使用展平的块列表。这样,我们需要的计算量就与 blocks_used 的总和成比例,而不是与 bs * max(num_blocks) 成比例。这个简化的图表展示了它的工作原理:

这种方法的主要困难在于,一个查询 token 可能使用了多个块,这阻碍了直接的 softmax 计算。然而,我们可以使用相同的方法分部分计算 softmax,然后进行重新调整。
第二个优化基于这样一个事实:在解码过程中,每个块通常只需要获取一次。由于该过程需要获取大部分 KV 缓存,因此可以使用连续的块。虽然从统一注意力算法的角度来看,此优化是可选的,但当前的统一批次创建过程假定它默认启用。
合并中间值 (Merging Intermediate Values)¶
统一注意力代码可以采用 3 条可选的代码路径:
- 因果注意力。
- 共享注意力。
- 唯一注意力。
这些代码路径中的每一个都返回一个三元组:如果该路径被跳过,则为 (local_attn, local_max, local_sum) 或 (None, None, None)。最后一步是合并部分值,重新调整它们,并使用先前描述的方法将它们组合起来。
统一/混合批次 (Unified/Mixed Batches)¶
统一注意力的主要优点之一是它不区分提示 token 和解码 token,并且整个注意力过程可以由单个函数计算,而无需中断突触图。这意味着我们不再需要对调度器输出进行任何预处理,例如对提示和解码进行排序和分离。统一注意力中活动的代码路径由注意力元数据中特定偏置张量的存在决定:
causal_bias=> 启用因果注意力。shared_bias=> 启用共享注意力。unique_bias=> 启用唯一注意力。
这意味着存在 8 种可能的代码路径,这在打印正在运行的特定配置时会得到反映。例如,阶段字符串“csu”表示所有 3 个代码路径都已使用,而“-u”表示仅运行唯一注意力。
大多数模型前向代码仅依赖于 query_len。在计算统一注意力时,另外两个维度很重要:num_shared_blocks 和 num_unique_blocks。当 contiguous_pa 为统一注意力启用时(目前强制执行),num_unique_blocks 等于需要使用的 KV 缓存切片的大小。此值取决于当前使用的 max(block_id)。
下一个考虑因素是是否包含 causal_attn。这取决于批次中是否存在提示样本。如果存在至少一个提示,则启用因果注意力。
最后,除了模型前向传递之外,该过程还取决于需要获取的 logits 数量,因为并非所有 token logits 都应传递给采样器。这通常会被填充到 max_num_seqs,但代码允许将来创建更详细的装箱方案。
总而言之,单个模型执行可以由以下元组表征:
(阶段, 查询长度, 共享块数, 唯一块数, logits 数)