分析特定提示或解码执行¶
此方法提供基本的 CPU 和 HPU 分析信息,例如操作的时间线和持续时间。
执行分析¶
要执行分析,请按照以下步骤操作
-
使用以下格式定义分析范围
其中
<phase>:阶段,prompt(提示)或 decode(解码)<batch_size>:要分析的批次大小<size>:输入长度(对于 prompt)或块数(对于 decode)-
<hpu_graph_flag>:指示是否包含 HPU 图的标志,t(true,真)或 f(false,假)例如,分析具有 256 个批次大小、2048 个块以及 HPU 图的解码,应具有此格式
-
使用适当的分析标志运行推理命令,如下例所示。
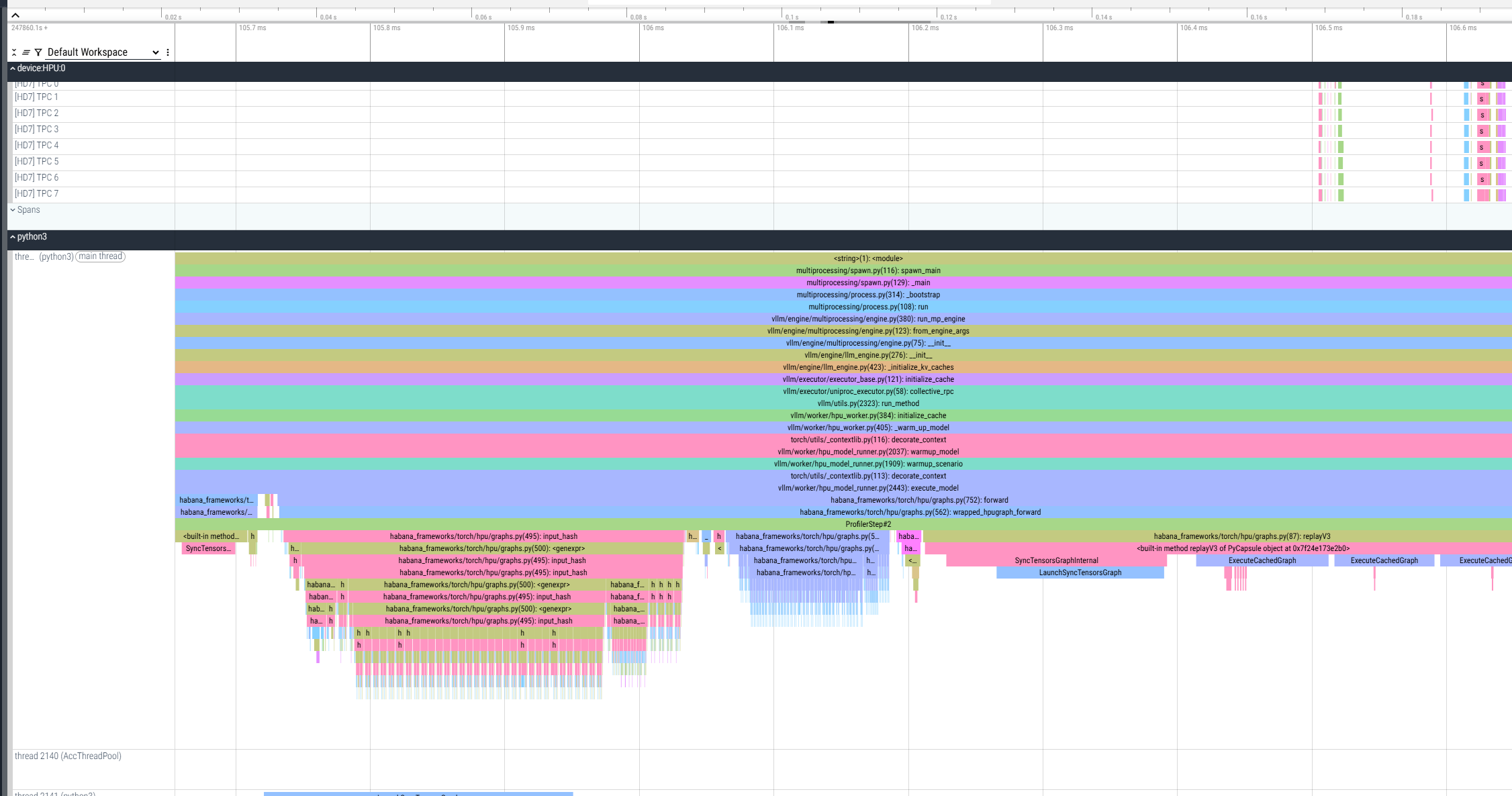
此分析模式在收集到所需的跟踪信息后,以故意触发断言结束。这是预期的行为,并且分析数据已成功收集。因此,会在当前工作目录中生成并保存一个 *.pt.trace.json.gz 文件。可以使用 Perfetto 查看它。
增强分析器配置¶
要获得有关设备级别行为的更详细见解,例如融合图结构、节点名称和跟踪分析器数据,请按照以下步骤增强分析器配置
-
配置分析器以收集详细跟踪。
-
设置以下标志。
-
使用增强配置运行分析。以下示例使用带有详细跟踪的解码分析。
因此,除了 *.pt.trace.json.gz 文件外,还会在当前目录中生成 .hltv 文件。
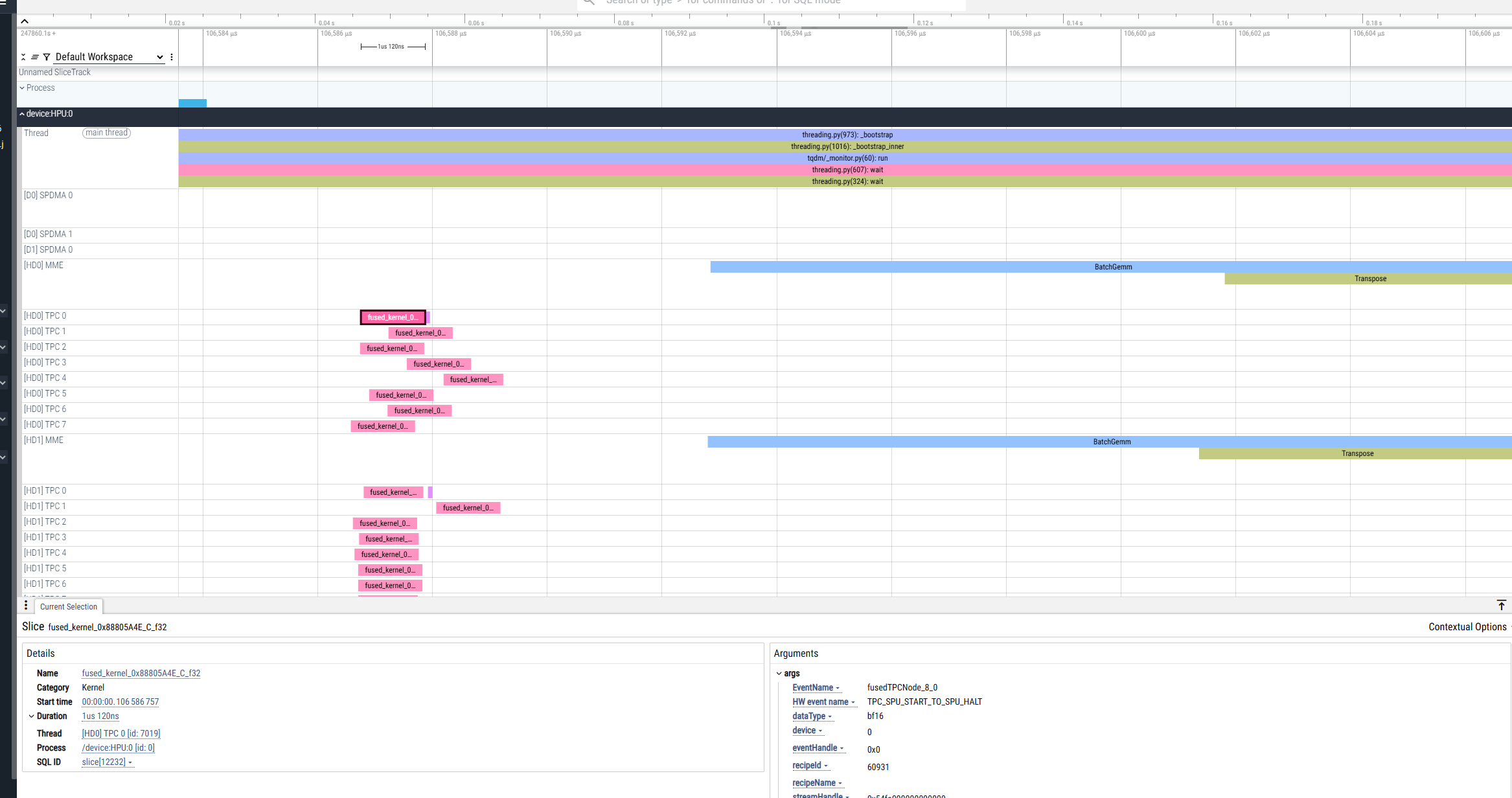
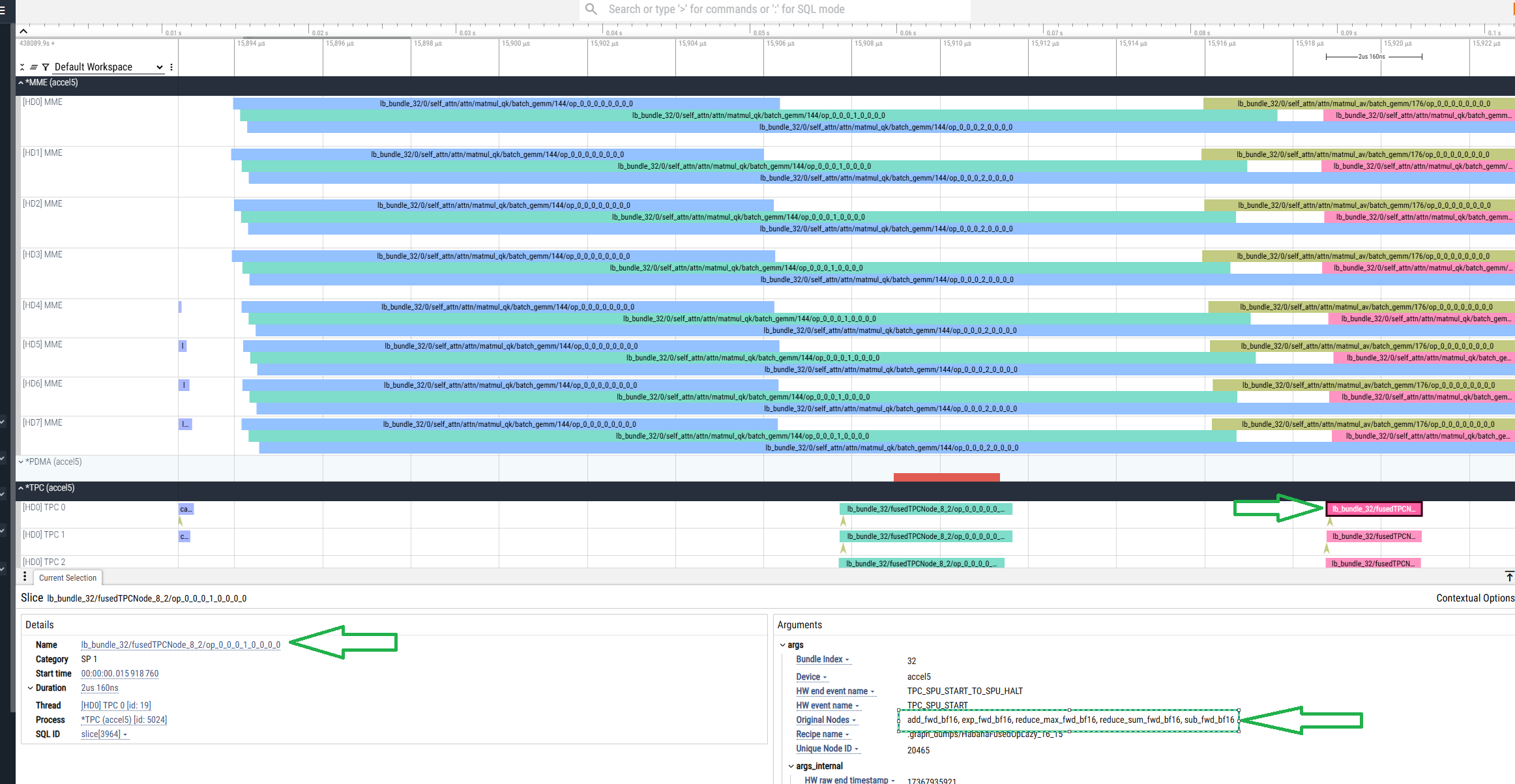
.hltv 文件包含节点名称、图结构以及每个融合操作内部内容的详细信息。