PyTorch 通过异步服务器进行分析¶
注意
此方法是端到端剖析的一部分,如果已完成端到端剖析,则无需单独执行。
要使用 PyTorch 跟踪工具分析 vLLM 服务器,请按照以下任一过程操作。
虽然您可以收集硬件跟踪,但我们不建议在通过异步服务器进行分析时这样做,因为它会显著增加跟踪文件的大小。有关硬件级别分析,请参阅 本文档。
通过单个请求分析服务器¶
-
禁用硬件跟踪以减小跟踪文件大小。如果要收集硬件跟踪,请跳过此步骤。
-
设置输出目录。
-
启动 vLLM 服务器。以下示例使用
facebook/opt-125m模型,TP=1,以及最大批次大小128。 -
等待预热完成并开始分析。
-
发送用于分析的请求。
-
停止分析。
通过多个请求分析服务器¶
-
禁用硬件跟踪以减小跟踪文件大小。如果要收集硬件跟踪,请跳过此步骤。
-
设置输出目录。
-
启动 vLLM 服务器。以下示例使用
facebook/opt-125m模型,TP=1,以及最大批次大小128。 -
安装
datasets包。 -
使用 vLLM 服务发送用于分析的请求。
vllm bench serve \ --backend vllm \ --model "facebook/opt-125m" \ --port 8080 \ --dataset-name "random" --random-input-len 128 --random-output-len 4 \ --random-range-ratio 1.0 \ --ignore-eos \ --profile \ --max-concurrency "4" \ --request-rate "inf" \ --num-prompts 4 \ --percentile-metrics "ttft,tpot,itl,e2el"
结果¶
执行此分析会生成一个 *.pt.trace.json.gz 文件,可以使用 Perfetto 打开。
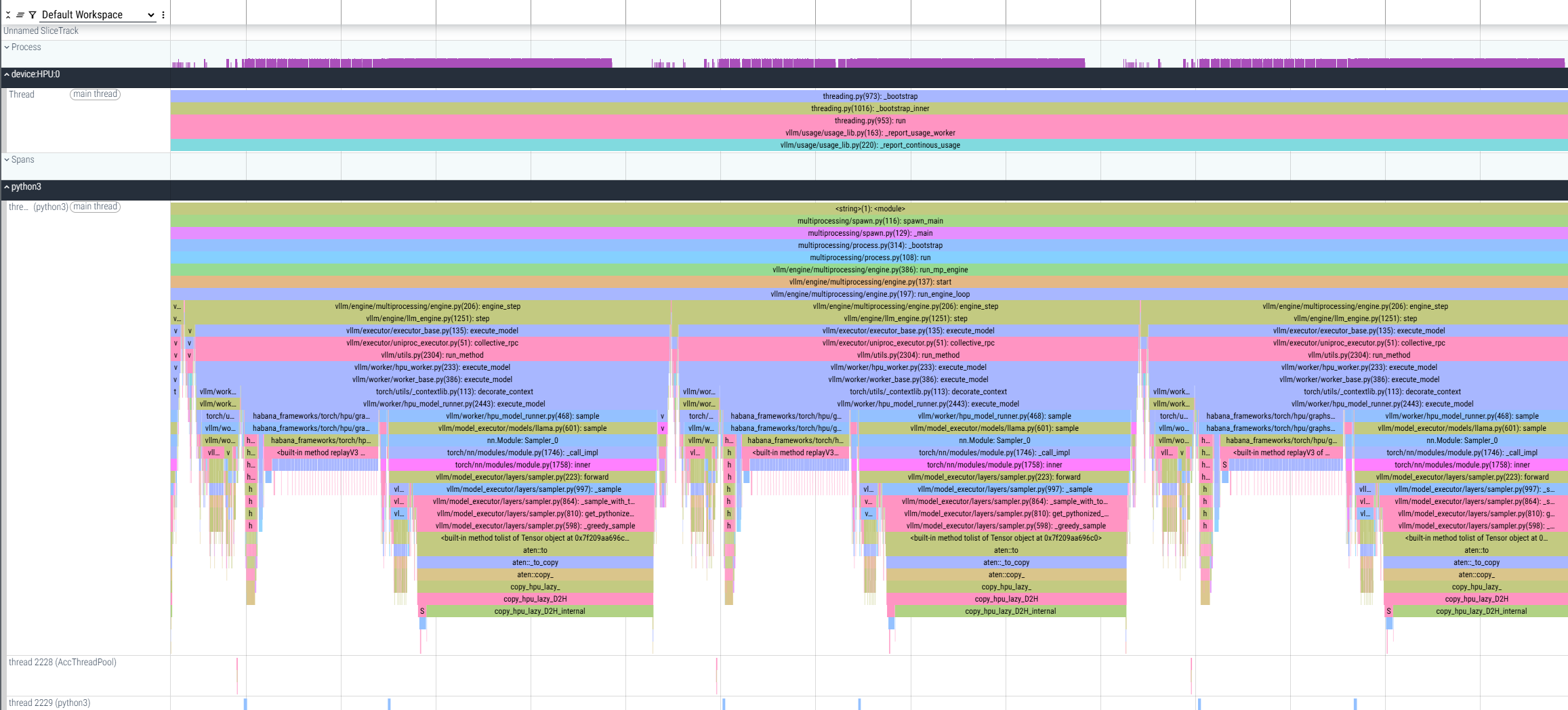
该文件显示了多个提示和解码的分析,其中测量了解码操作,并且还可以观察它们之间的主机端延迟以进行分析。