Dify¶
Dify 是一个开源的大模型应用开发平台。它直观的界面结合了智能体AI工作流、RAG管线、智能体能力、模型管理、可观测性功能等,让您能够快速从原型部署到生产环境。
它支持vLLM作为模型提供商,以高效地服务大型语言模型。
本指南将引导您使用vLLM后端部署Dify。
先决条件¶
- 设置 vLLM 环境
- 安装 Docker 和 Docker Compose
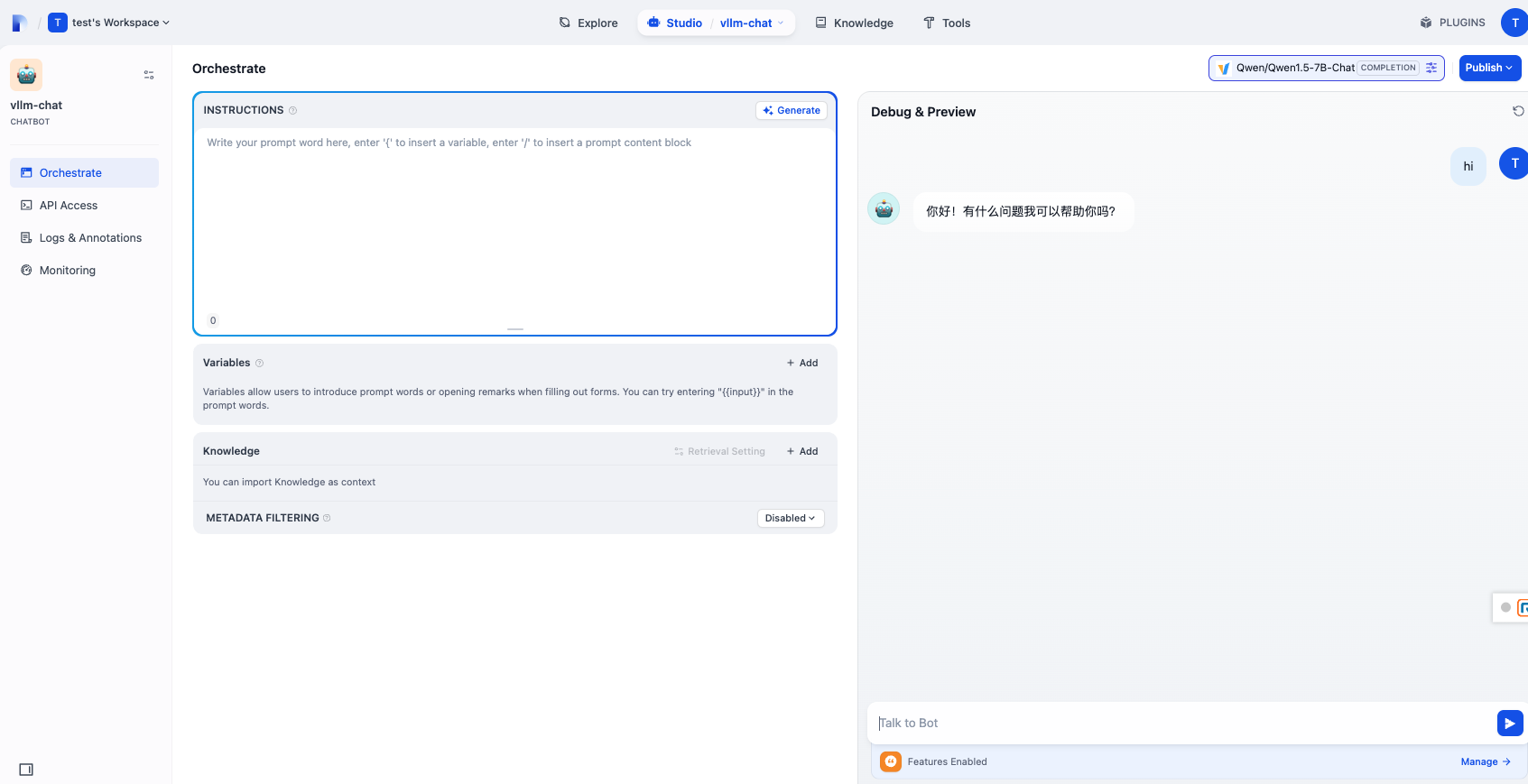
部署¶
- 启动支持聊天完成模型的 vLLM 服务器,例如
- 使用docker compose启动Dify服务器(详情)
git clone https://github.com/langgenius/dify.git
cd dify
cd docker
cp .env.example .env
docker compose up -d
-
打开浏览器访问
https:///install,配置基本登录信息并登录。 -
在右上角用户菜单(个人资料图标下)中,进入“设置”,然后点击“模型提供商”,找到并安装
vLLM提供商。 -
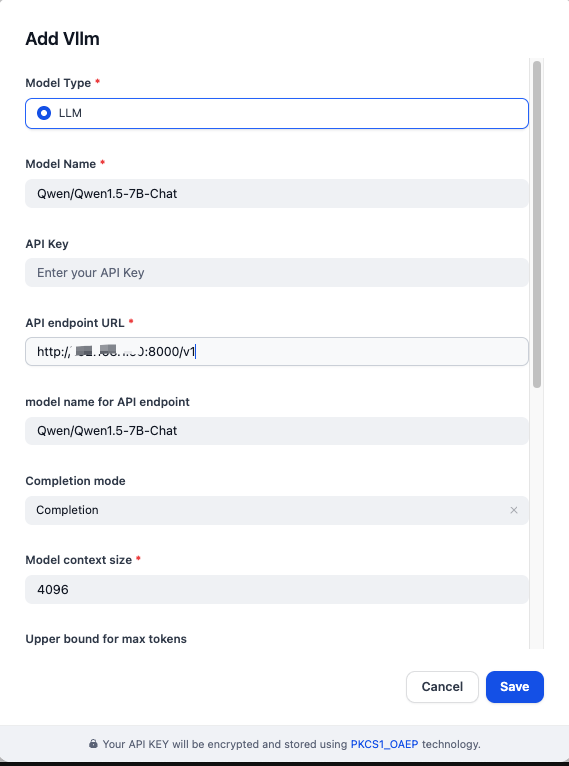
按如下填写模型提供商详情:
- 模型类型:
LLM - 模型名称:
Qwen/Qwen1.5-7B-Chat - API 端点 URL:
http://{vllm_server_host}:{vllm_server_port}/v1 - API 端点模型名称:
Qwen/Qwen1.5-7B-Chat - 补全模式:
Completion
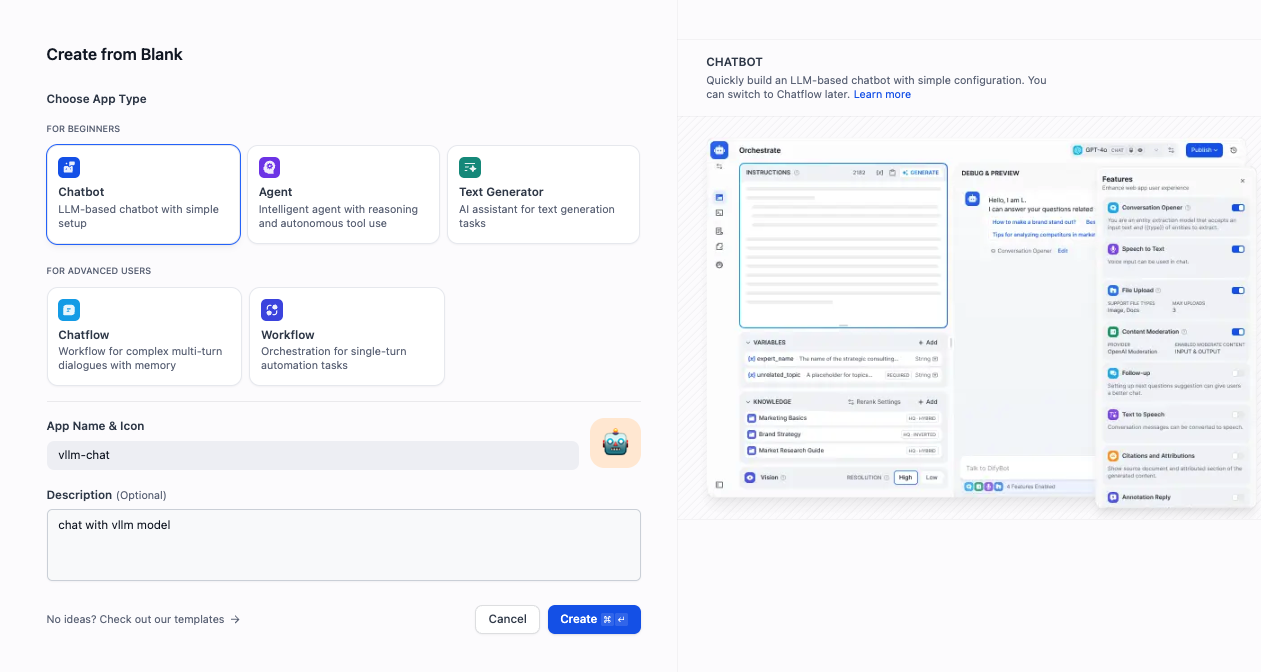
- 要创建一个测试聊天机器人,请前往
Studio → 聊天机器人 → 从空白创建,然后选择“聊天机器人”作为类型。
- 点击您刚刚创建的聊天机器人以打开聊天界面并开始与模型交互。