Helm¶
用于在 Kubernetes 上部署 vLLM 的 Helm Chart
Helm 是 Kubernetes 的包管理器。它有助于自动化 vLLM 应用在 Kubernetes 上的部署。使用 Helm,您可以通过覆盖变量值,将相同的框架架构以不同的配置部署到多个命名空间。
本指南将引导您完成使用 Helm 部署 vLLM 的过程,包括必要的先决条件、Helm 安装步骤以及架构和值文件的文档。
先决条件¶
在开始之前,请确保您具备以下条件
- 正在运行的 Kubernetes 集群
- NVIDIA Kubernetes 设备插件 (
k8s-device-plugin):可在此处找到 https://github.com/NVIDIA/k8s-device-plugin - 集群中可用的 GPU 资源
- 包含待部署模型的 S3 存储桶
安装 Chart¶
使用发布名称 test-vllm 安装 Chart
helm upgrade --install --create-namespace \
--namespace=ns-vllm test-vllm . \
-f values.yaml \
--set secrets.s3endpoint=$ACCESS_POINT \
--set secrets.s3bucketname=$BUCKET \
--set secrets.s3accesskeyid=$ACCESS_KEY \
--set secrets.s3accesskey=$SECRET_KEY
卸载 Chart¶
要卸载 test-vllm 部署
该命令会移除与 Chart 相关的所有 Kubernetes 组件,**包括持久卷**,并删除该发布。
架构¶
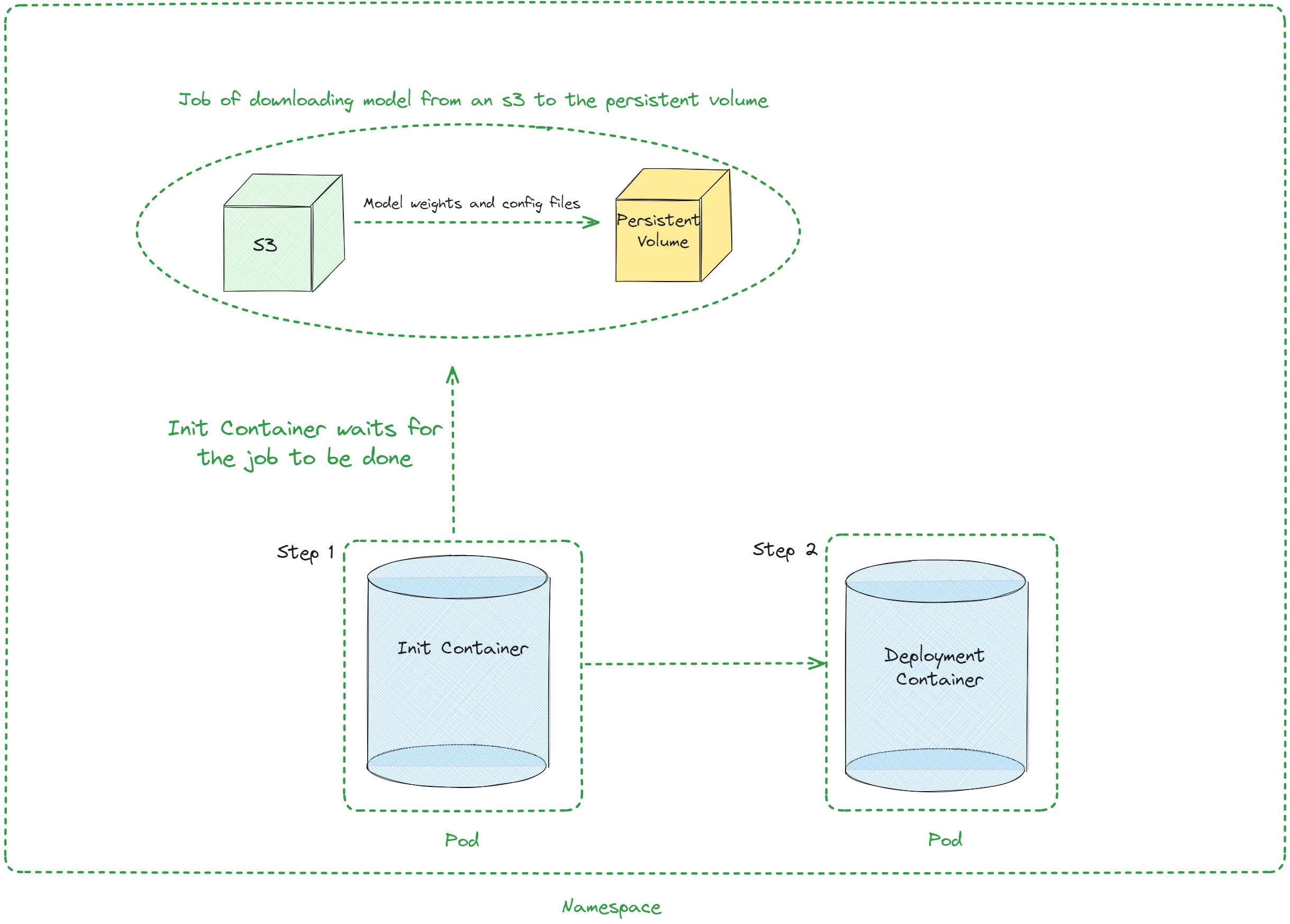
参数值¶
下表描述了 values.yaml 中 Chart 的可配置参数
| 键 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| autoscaling | 对象 | {"enabled":false,"maxReplicas":100,"minReplicas":1,"targetCPUUtilizationPercentage":80} | 自动扩缩配置 |
| autoscaling.enabled | 布尔值 | false | 启用自动扩缩 |
| autoscaling.maxReplicas | 整型 | 100 | 最大副本数 |
| autoscaling.minReplicas | 整型 | 1 | 最小副本数 |
| autoscaling.targetCPUUtilizationPercentage | 整型 | 80 | 自动扩缩的目标 CPU 利用率 |
| configs | 对象 | {} | Configmap |
| containerPort | 整型 | 8000 | 容器端口 |
| customObjects | 列表 | [] | 自定义对象配置 |
| deploymentStrategy | 对象 | {} | 部署策略配置 |
| externalConfigs | 列表 | [] | 外部配置 |
| extraContainers | 列表 | [] | 额外容器配置 |
| extraInit | 对象 | {"pvcStorage":"1Gi","s3modelpath":"relative_s3_model_path/opt-125m", "awsEc2MetadataDisabled": true} | 初始化容器的额外配置 |
| extraInit.pvcStorage | 字符串 | "1Gi" | S3 存储桶的存储大小 |
| extraInit.s3modelpath | 字符串 | "relative_s3_model_path/opt-125m" | 托管模型权重和配置文件的 S3 存储桶上的模型路径 |
| extraInit.awsEc2MetadataDisabled | 布尔值 | true | 禁用 Amazon EC2 实例元数据服务的使用 |
| extraPorts | 列表 | [] | 额外端口配置 |
| gpuModels | 列表 | ["TYPE_GPU_USED"] | 使用的 GPU 类型 |
| image | 对象 | {"command":["vllm","serve","/data/","--served-model-name","opt-125m","--host","0.0.0.0","--port","8000"],"repository":"vllm/vllm-openai","tag":"latest"} | 镜像配置 |
| image.command | 列表 | ["vllm","serve","/data/","--served-model-name","opt-125m","--host","0.0.0.0","--port","8000"] | 容器启动命令 |
| image.repository | 字符串 | "vllm/vllm-openai" | 镜像仓库 |
| image.tag | 字符串 | "latest" | 镜像标签 |
| livenessProbe | 对象 | {"failureThreshold":3,"httpGet":{"path":"/health","port":8000},"initialDelaySeconds":15,"periodSeconds":10} | 存活探针配置 |
| livenessProbe.failureThreshold | 整型 | 3 | 探针连续失败的次数,在此之后 Kubernetes 会认为整体检查失败:容器不再存活 |
| livenessProbe.httpGet | 对象 | {"path":"/health","port":8000} | 服务器上 kubelet http 请求的配置 |
| livenessProbe.httpGet.path | 字符串 | "/health" | HTTP 服务器上的访问路径 |
| livenessProbe.httpGet.port | 整型 | 8000 | 要访问的容器端口的名称或编号,服务器在该端口上监听 |
| livenessProbe.initialDelaySeconds | 整型 | 15 | 容器启动后到存活探针开始执行前的秒数 |
| livenessProbe.periodSeconds | 整型 | 10 | 执行存活探针的频率(秒) |
| maxUnavailablePodDisruptionBudget | 字符串 | "" | 干扰预算配置 |
| readinessProbe | 对象 | {"failureThreshold":3,"httpGet":{"path":"/health","port":8000},"initialDelaySeconds":5,"periodSeconds":5} | 就绪探针配置 |
| readinessProbe.failureThreshold | 整型 | 3 | 探针连续失败的次数,在此之后 Kubernetes 会认为整体检查失败:容器未就绪 |
| readinessProbe.httpGet | 对象 | {"path":"/health","port":8000} | 服务器上 kubelet http 请求的配置 |
| readinessProbe.httpGet.path | 字符串 | "/health" | HTTP 服务器上的访问路径 |
| readinessProbe.httpGet.port | 整型 | 8000 | 要访问的容器端口的名称或编号,服务器在该端口上监听 |
| readinessProbe.initialDelaySeconds | 整型 | 5 | 容器启动后到就绪探针开始执行前的秒数 |
| readinessProbe.periodSeconds | 整型 | 5 | 执行就绪探针的频率(秒) |
| replicaCount | 整型 | 1 | 副本数 |
| resources | 对象 | {"limits":{"cpu":4,"memory":"16Gi","nvidia.com/gpu":1},"requests":{"cpu":4,"memory":"16Gi","nvidia.com/gpu":1}} | 资源配置 |
| resources.limits."nvidia.com/gpu" | 整型 | 1 | 使用的 GPU 数量 |
| resources.limits.cpu | 整型 | 4 | CPU 数量 |
| resources.limits.memory | 字符串 | "16Gi" | CPU 内存配置 |
| resources.requests."nvidia.com/gpu" | 整型 | 1 | 使用的 GPU 数量 |
| resources.requests.cpu | 整型 | 4 | CPU 数量 |
| resources.requests.memory | 字符串 | "16Gi" | CPU 内存配置 |
| secrets | 对象 | {} | 密钥配置 |
| serviceName | 字符串 | "" | 服务名称 |
| servicePort | 整型 | 80 | 服务端口 |
| labels.environment | 字符串 | test | 环境名称 |