架构概览¶
本文档提供了 vLLM 架构的概览。
入口点¶
vLLM 提供了多个与系统交互的入口点。下图展示了它们之间的关系。
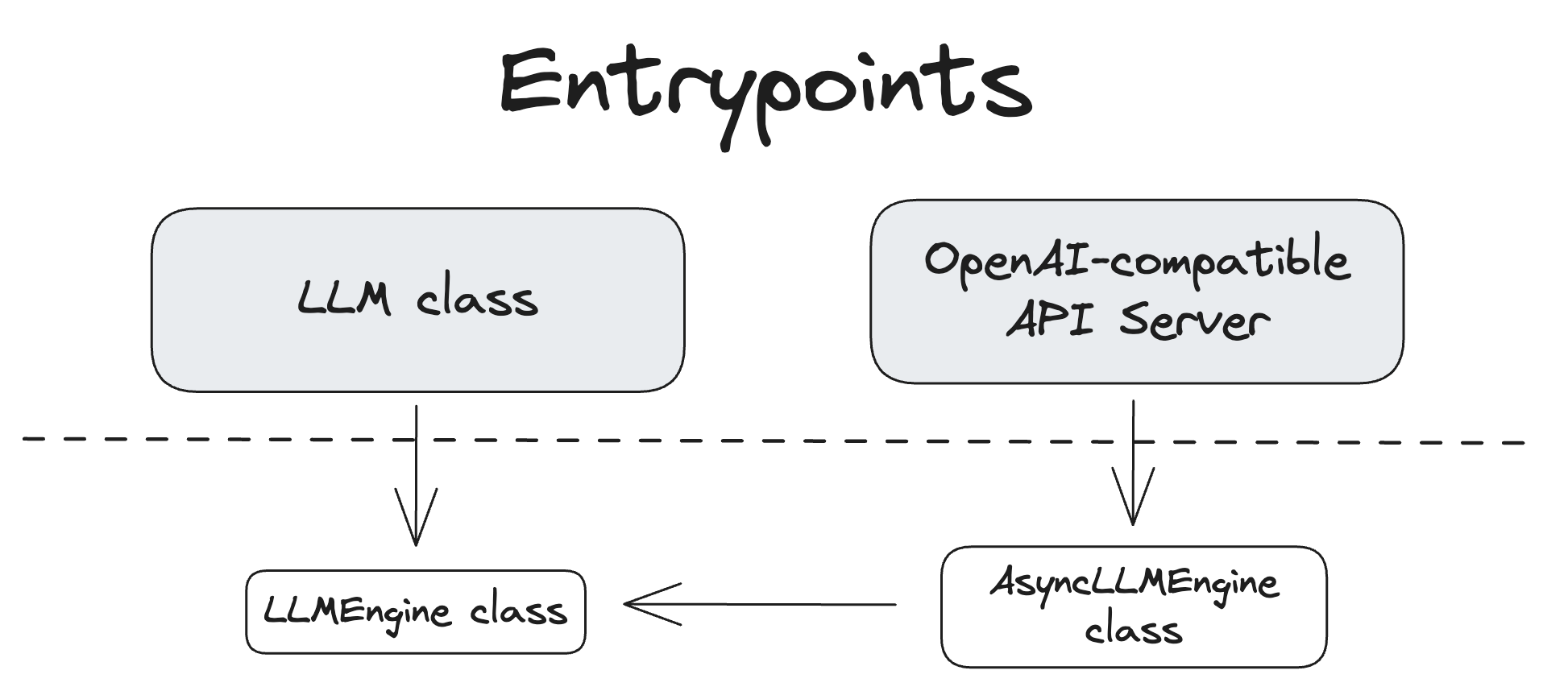
LLM 类¶
LLM 类提供了主要的 Python 接口,用于执行离线推理,即不使用单独的模型推理服务器即可与模型交互。
以下是 LLM 类用法的示例:
代码
from vllm import LLM, SamplingParams
# Define a list of input prompts
prompts = [
"Hello, my name is",
"The capital of France is",
"The largest ocean is",
]
# Define sampling parameters
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
# Initialize the LLM engine with the OPT-125M model
llm = LLM(model="facebook/opt-125m")
# Generate outputs for the input prompts
outputs = llm.generate(prompts, sampling_params)
# Print the generated outputs
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
更多 API 详情请参阅 API 文档的离线推理部分。
LLM 类的代码可以在 vllm/entrypoints/llm.py 中找到。
OpenAI 兼容 API 服务器¶
vLLM 的第二个主要接口是通过其 OpenAI 兼容 API 服务器。该服务器可以使用 vllm serve 命令启动。
vllm CLI 的代码可以在 vllm/entrypoints/cli/main.py 中找到。
有时您可能会看到 API 服务器入口点被直接使用,而非通过 vllm CLI 命令。例如:
该代码可以在 vllm/entrypoints/openai/api_server.py 中找到。
更多关于 API 服务器的详情,请参阅 OpenAI 兼容服务器文档。
LLM 引擎¶
LLMEngine 和 AsyncLLMEngine 类是 vLLM 系统运行的核心,负责处理模型推理和异步请求处理。
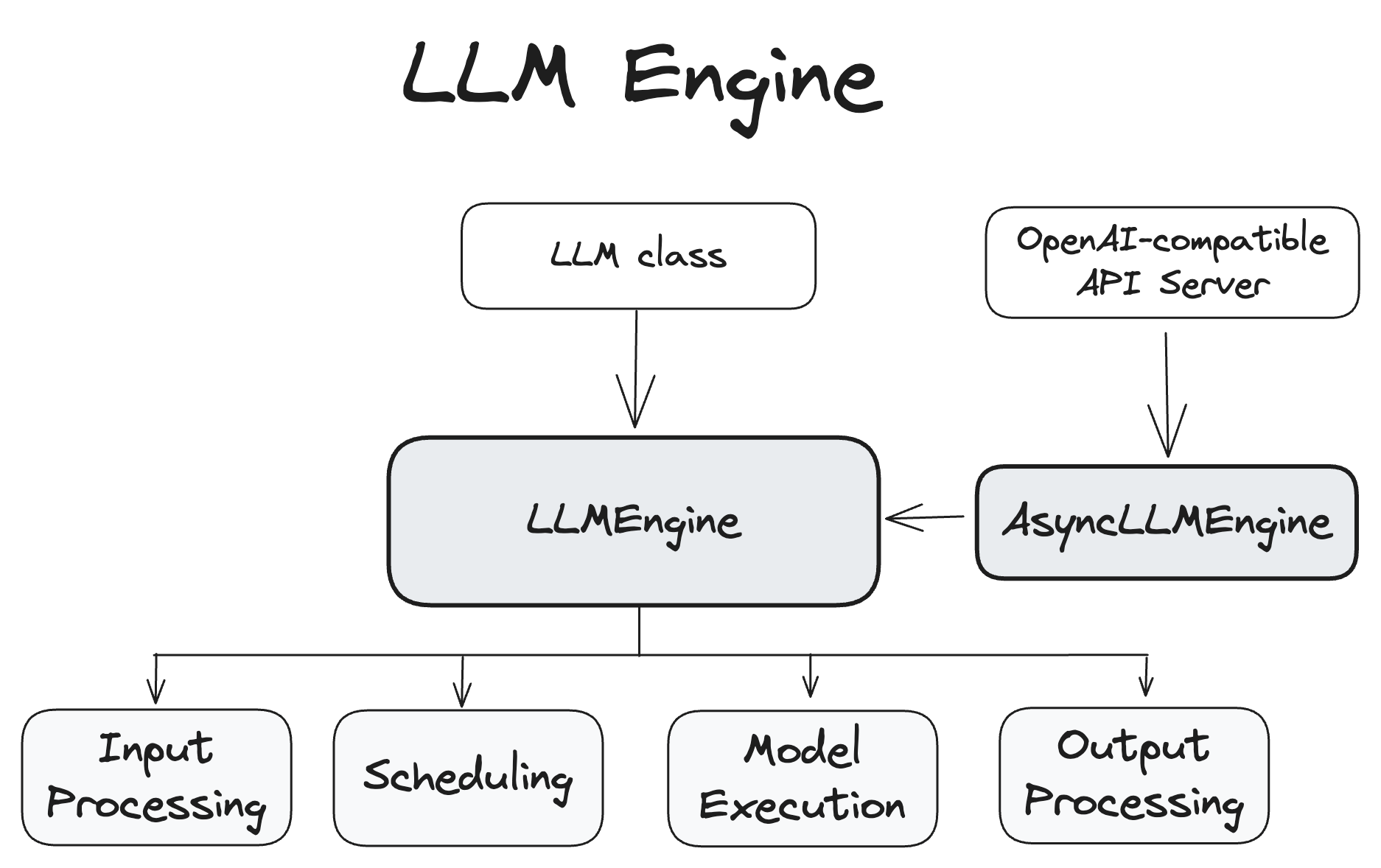
LLMEngine¶
LLMEngine 类是 vLLM 引擎的核心组件。它负责接收客户端请求并从模型生成输出。LLMEngine 包括输入处理、模型执行(可能分布在多个主机和/或 GPU 上)、调度和输出处理。
- 输入处理:使用指定的 Tokenizer 处理输入文本的分词。
- 调度:选择在每个步骤中处理哪些请求。
- 模型执行:管理语言模型的执行,包括跨多个 GPU 的分布式执行。
- 输出处理:处理模型生成的输出,将语言模型中的 token ID 解码为人类可读的文本。
LLMEngine 的代码可以在 vllm/engine/llm_engine.py 中找到。
AsyncLLMEngine¶
AsyncLLMEngine 类是 LLMEngine 类的一个异步封装。它使用 asyncio 创建一个后台循环,持续处理传入请求。AsyncLLMEngine 专为在线服务设计,可以处理多个并发请求并将输出流式传输到客户端。
OpenAI 兼容 API 服务器使用 AsyncLLMEngine。还有一个演示 API 服务器作为更简单的示例,位于 vllm/entrypoints/api_server.py。
AsyncLLMEngine 的代码可以在 vllm/engine/async_llm_engine.py 中找到。
Worker¶
Worker 是运行模型推理的进程。vLLM 遵循使用一个进程控制一个加速设备(如 GPU)的常见做法。例如,如果使用大小为 2 的张量并行和大小为 2 的流水线并行,则总共有 4 个 Worker。Worker 通过其 rank 和 local_rank 进行标识。rank 用于全局编排,而 local_rank 主要用于分配加速设备以及访问文件系统和共享内存等本地资源。
Model Runner¶
每个 Worker 都含有一个 Model Runner 对象,负责加载和运行模型。大部分模型执行逻辑都位于此处,例如准备输入张量和捕获 CUDA 图。
模型¶
每个 Model Runner 对象都含有一个模型对象,即实际的 torch.nn.Module 实例。有关不同配置如何影响最终获得的类,请参阅 huggingface_integration。
类层次结构¶
下图展示了 vLLM 的类层次结构:
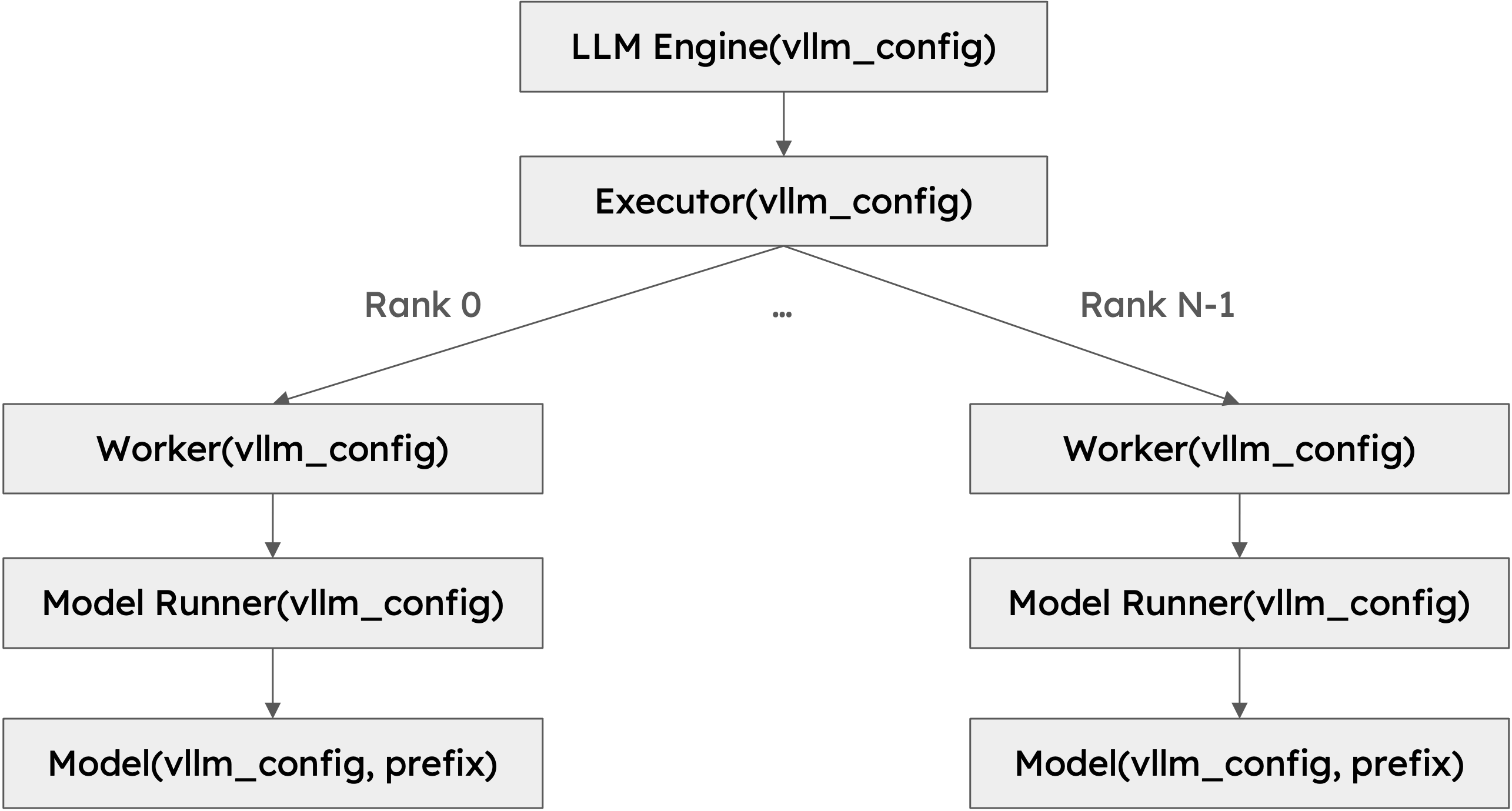
该类层次结构背后有几个重要的设计选择:
1. 可扩展性:层次结构中的所有类都接受一个包含所有必要信息的配置对象。VllmConfig 类是主要且广泛传递的配置对象。类层次结构相当深,每个类都需要读取其感兴趣的配置。通过将所有配置封装在一个对象中,我们可以轻松地传递配置对象并访问所需的配置。假设我们想添加一个只涉及 Model Runner 的新功能(考虑到 LLM 推理领域发展之快,这种情况很常见)。我们必须在 VllmConfig 类中添加一个新的配置选项。由于我们传递的是整个配置对象,所以我们只需要将配置选项添加到 VllmConfig 类中,Model Runner 就可以直接访问它。我们无需更改引擎、Worker 或模型类的构造函数来传递新的配置选项。
2. 一致性:Model Runner 需要统一的接口来创建和初始化模型。vLLM 支持 50 多种流行的开源模型。每种模型都有自己的初始化逻辑。如果构造函数签名因模型而异,Model Runner 将不知道如何相应地调用构造函数,这将导致复杂且容易出错的检查逻辑。通过统一模型类的构造函数,Model Runner 可以轻松地创建和初始化模型,而无需了解具体的模型类型。这对于组合模型也很有用。视觉-语言模型通常由视觉模型和语言模型组成。通过统一构造函数,我们可以轻松地创建视觉模型和语言模型,并将它们组合成一个视觉-语言模型。
注意
为支持此更改,所有 vLLM 模型的签名已更新为:
为避免意外传递不正确的参数,构造函数现在仅接受关键字参数。这确保了如果传递旧配置,构造函数将引发错误。vLLM 开发者已经为 vLLM 中的所有模型进行了此更改。对于非树内注册模型,开发者需要更新其模型,例如通过添加 shim 代码来使旧的构造函数签名适应新的签名。
代码
class MyOldModel(nn.Module):
def __init__(
self,
config,
cache_config: Optional[CacheConfig] = None,
quant_config: Optional[QuantizationConfig] = None,
lora_config: Optional[LoRAConfig] = None,
prefix: str = "",
) -> None:
...
from vllm.config import VllmConfig
class MyNewModel(MyOldModel):
def __init__(self, *, vllm_config: VllmConfig, prefix: str = ""):
config = vllm_config.model_config.hf_config
cache_config = vllm_config.cache_config
quant_config = vllm_config.quant_config
lora_config = vllm_config.lora_config
super().__init__(config, cache_config, quant_config, lora_config, prefix)
if __version__ >= "0.6.4":
MyModel = MyNewModel
else:
MyModel = MyOldModel
通过这种方式,模型可以兼容 vLLM 的旧版本和新版本。
3. 初始化时的分片和量化:某些功能需要更改模型权重。例如,张量并行需要对模型权重进行分片,而量化需要对模型权重进行量化。实现此功能有两种可能的方法。一种是在模型初始化后更改模型权重,另一种是在模型初始化期间更改模型权重。vLLM 选择了后者。第一种方法对于大型模型而言不可扩展。假设我们想在 16 个 H100 80GB GPU 上运行一个 405B 模型(大约 810GB 权重)。理想情况下,每个 GPU 应该只加载 50GB 权重。如果我们在模型初始化后更改模型权重,我们需要将完整的 810GB 权重加载到每个 GPU,然后进行分片,这将导致巨大的内存开销。相反,如果我们在模型初始化期间对权重进行分片,则每一层只会创建其所需权重的一个分片,从而大大减少内存开销。相同的思想也适用于量化。请注意,我们还在模型的构造函数中添加了一个额外的参数 prefix,以便模型可以根据该前缀进行不同的初始化。这对于非均匀量化很有用,即模型的不同部分以不同方式进行量化。prefix 通常对于顶层模型是空字符串,对于子模型则是诸如 "vision" 或 "language" 这样的字符串。通常,它与检查点文件中模块状态字典的名称匹配。
这种设计的一个缺点是,很难为 vLLM 中的单个组件编写单元测试,因为每个组件都需要通过一个完整的配置对象进行初始化。我们通过提供一个默认初始化函数来解决这个问题,该函数创建一个所有字段都设置为 None 的默认配置对象。如果我们要测试的组件只关心配置对象中的几个字段,我们可以创建一个默认配置对象并设置我们关心的字段。通过这种方式,我们可以独立地测试该组件。请注意,vLLM 中的许多测试都是端到端测试,用于测试整个系统,因此这不是一个大问题。
总而言之,完整的配置对象 VllmConfig 可以被视为一个引擎级别的全局状态,在所有 vLLM 类之间共享。