自动前缀缓存¶
前缀缓存 KV 缓存块是 LLM 推理中一种流行的优化方法,可避免冗余的提示计算。其核心思想很简单——我们缓存已处理请求的 KV 缓存块,并在新请求带有与之前请求相同的前缀时重用这些块。由于前缀缓存几乎是免费的午餐,且不会改变模型输出,因此它已被许多公共端点(例如 OpenAI、Anthropic 等)和大多数开源 LLM 推理框架(例如 SGLang)广泛使用。
虽然有多种实现前缀缓存的方法,但 vLLM 选择了一种基于哈希的方法。具体来说,我们通过块中的 token 和块前缀中的 token 对每个 KV 缓存块进行哈希处理。
Block 1 Block 2 Block 3
[A gentle breeze stirred] [the leaves as children] [laughed in the distance]
Block 1: |<--- block tokens ---->|
Block 2: |<------- prefix ------>| |<--- block tokens --->|
Block 3: |<------------------ prefix -------------------->| |<--- block tokens ---->|
在上面的示例中,第一个块中的 KV 缓存可以通过 token“A gentle breeze stirred”唯一标识。第三个块可以通过块中的 token“laughed in the distance”以及前缀 token“A gentle breeze stirred the leaves as children”唯一标识。因此,我们可以构建 hash(tuple[components]) 的块哈希,其中 components 是
- 父哈希值:父哈希块的哈希值。
- 块 token:此块中 token 的元组。包含精确 token 的原因是为了减少潜在的哈希值冲突。
- 额外哈希:使此块独一无二所需的其他值,例如 LoRA ID、多模态输入哈希(参见下面的示例)以及用于在多租户环境中隔离缓存的缓存盐值。
注意 1: 我们只缓存完整的块。
注意 2: 上述哈希键结构并非 100% 无冲突。理论上,不同的前缀 token 仍然可能具有相同的哈希值。为了避免在多租户设置中出现任何哈希冲突,我们建议使用 SHA256 作为哈希函数,而不是默认的内置哈希。SHA256 从 vLLM v0.8.3 开始支持,并且必须通过命令行参数启用。它会对性能产生约每 token 100-200 纳秒的影响(对于 5 万 token 的上下文,约 6 毫秒)。
多模态输入的哈希示例
在此示例中,我们将说明前缀缓存如何与多模态输入(例如图像)一起工作。假设我们有一个包含以下消息的请求
messages = [
{"role": "user",
"content": [
{"type": "text",
"text": "What's in this image?"
},
{"type": "image_url",
"image_url": {"url": image_url},
},
]},
]
它将变为以下提示
Prompt:
<s>[INST]What's in this image?\n[IMG][/INST]
Tokenized prompt:
[1, 3, 7493, 1681, 1294, 1593, 3937, 9551, 10, 4]
Prompt with placeholders (<P>):
[1, 3, 7493, 1681, 1294, 1593, 3937, 9551, <P>, <P>, ..., <P>, 4]
正如我们所看到的,在分词之后,[IMG] 将被一系列占位符 token 替换,而这些占位符在预填充期间将被图像嵌入替换。前缀缓存支持这种情况的挑战在于,我们需要区分图像和占位符。为了解决这个问题,我们对前端图像处理器生成的图像哈希进行编码。例如,上述提示中块的哈希将是(假设块大小为 16,我们有 41 个占位符 token)
Block 0
Parent hash: None
Token IDs: 1, 3, 7493, 1681, 1294, 1593, 3937, 9551, <p>, ..., <p>
Extra hash: <image hash>
Block 1
Parent hash: Block 0 hash
Token IDs: <p>, ..., <p>
Extra hash: <image hash>
Block 2
Parent hash: Block 1 hash
Token IDs: <p>, ..., <p>
Extra hash: <image hash>
Block 3
Parent hash: Block 2 hash
Token IDs: <p>, ..., <p>, 4
Extra hash: <image hash>
在本文档的其余部分,我们首先介绍 vLLM v1 中用于前缀缓存的数据结构,然后是主要 KV 缓存操作符(例如,分配、追加、释放、驱逐)的前缀缓存工作流程。最后,我们通过一个示例来演示端到端的前缀缓存工作流程。
缓存隔离以提高安全性 为了提高共享环境中的隐私性,vLLM 支持通过可选的每个请求加盐来隔离前缀缓存重用。通过在请求中包含一个 cache_salt,此值将被注入到第一个块的哈希中,从而确保只有具有相同盐值的请求才能重用缓存的 KV 块。这可以防止攻击者通过观察延迟差异来推断缓存内容的基于时间的攻击。这在不影响性能的情况下提供了保护。
{
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Here is a document with details about the world series: ..."},
{"role": "user", "content": "Who won the world series in 2020?"}
],
"cache_salt": "your-cache-salt"
}
通过此设置,缓存共享仅限于明确同意使用公共盐的用户或请求,从而实现在信任组内的缓存重用,同时隔离其他组。
注意: 引擎 V0 不支持缓存隔离。
数据结构¶
vLLM v1 中的前缀缓存是在 KV 缓存管理器中实现的。其基本构建块是“块”数据类(简化版)
class KVCacheBlock:
# The block ID (immutable)
block_id: int
# The block hash (will be assigned when the block is full,
# and will be reset when the block is evicted).
block_hash: BlockHash
# The number of requests using this block now.
ref_cnt: int
# The pointers to form a doubly linked list for the free queue.
prev_free_block: Optional["KVCacheBlock"] = None
next_free_block: Optional["KVCacheBlock"] = None
有两点设计需要强调
- 我们在初始化 KV 缓存管理器时分配所有 KVCacheBlock 作为块池。这避免了 Python 对象创建的开销,并且可以轻松地持续跟踪所有块。
- 我们直接在 KVCacheBlock 中引入双向链表指针,以便可以直接构建空闲队列。这给我们带来了两个好处
- 我们可以实现将中间元素移动到尾部的 O(1) 复杂度。
- 我们可以避免引入另一个 Python 队列(例如
deque),因为它对元素有封装。
因此,当 KV 缓存管理器初始化时,我们将拥有以下组件
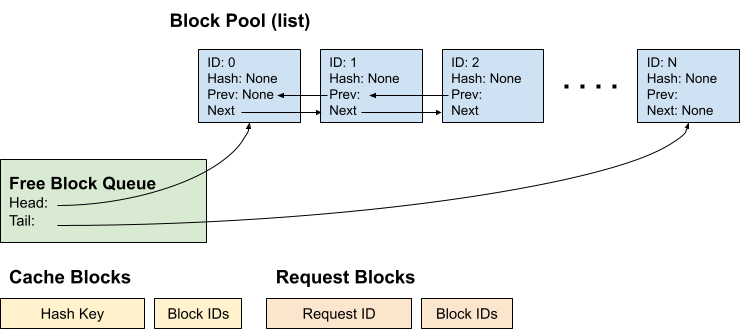
- 块池:KVCacheBlock 的列表。
- 空闲块队列:仅存储头块和尾块的指针以进行操作。
- 缓存块:从哈希键到块 ID 的映射。
- 请求块:从请求 ID 到已分配块 ID 的映射。
操作¶
块分配¶
新请求: 调度器调度带有 KV 缓存块分配的新请求的工作流程
- 调度器调用
kv_cache_manager.get_computed_blocks()来获取一系列已计算的块。这是通过对请求中的提示 token 进行哈希并查找缓存块来完成的。 - 调度器调用
kv_cache_manager.allocate_slots()。它执行以下步骤- 计算所需新块的数量,如果没有足够的块可分配则返回。
- “触碰”已计算的块。它将已计算块的引用计数增加一,如果该块未被其他请求使用,则将其从空闲队列中移除。这是为了避免这些已计算的块被驱逐。有关说明,请参阅下一节中的示例。
- 通过弹出空闲队列的头部来分配新块。如果头部块是缓存块,这也“驱逐”该块,以便从现在开始其他请求不能再重用它。
- 如果一个已分配的块已经满了 token,我们立即将其添加到缓存块中,以便同一批次中的其他请求可以重用该块。
正在运行的请求: 调度器调度带有 KV 缓存块分配的正在运行请求的工作流程
- 调度器调用
kv_cache_manager.allocate_slots()。它执行以下步骤- 计算所需新块的数量,如果没有足够的块可分配则返回。
- 通过弹出空闲队列的头部来分配新块。如果头部块是缓存块,这也“驱逐”该块,以便从现在开始其他请求不能再重用它。
- 将 token ID 追加到现有块以及新块的槽位中。如果一个块已满,我们将其添加到缓存块以进行缓存。
重复块
假设块大小为 4,您发送一个请求(请求 1),其提示为 ABCDEF,解码长度为 3
Prompt: [A, B, C, D, E, F]
Output: [G, H, I]
Time 0:
Tokens: [A, B, C, D, E, F, G]
Block Table: [0 (ABCD), 1 (EFG)]
Cache Blocks: 0
Time 1:
Tokens: [A, B, C, D, E, F, G, H]
Block Table: [0 (ABCD), 1 (EFGH)]
Cache Blocks: 0, 1
Time 2:
Tokens: [A, B, C, D, E, F, G, H, I]
Block Table: [0 (ABCD), 1 (EFGH), 2 (I)]
Cache Blocks: 0, 1
现在块 0 和块 1 被缓存,我们再次使用贪婪采样发送相同的请求(请求 2),以便它将产生与请求 1 完全相同的输出
Prompt: [A, B, C, D, E, F]
Output: [G, H, I]
Time 0:
Tokens: [A, B, C, D, E, F, G]
Block Table: [0 (ABCD), 3 (EFG)]
Cache Blocks: 0, 1
Time 1:
Tokens: [A, B, C, D, E, F, G, H]
Block Table: [0 (ABCD), 3 (EFGH)]
Cache Blocks: 0, 1, 3
可以看出,块 3 是一个新的完整块并被缓存。然而,它与块 1 是冗余的,这意味着我们缓存了相同的块两次。在 v0 中,当检测到块 3 重复时,我们释放块 3 并让请求 2 使用块 1,因此其块表在时间 1 变为 [0, 1]。然而,vLLM v1 中的块表是只追加的,这意味着不允许将块表从 [0, 3] 更改为 [0, 1]。因此,我们将为哈希键 E-H 拥有重复的块。这种重复将在请求被释放时消除。
释放¶
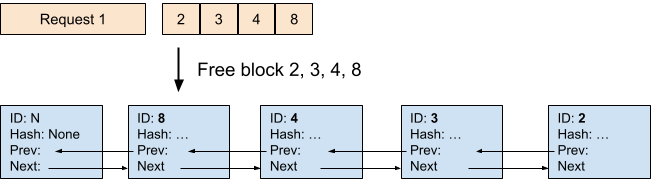
当请求完成后,如果没有其他请求正在使用其块(引用计数 = 0),我们将释放其所有块。在此示例中,我们释放请求 1 以及与其关联的块 2、3、4、8。我们可以看到,被释放的块以反向顺序添加到空闲队列的尾部。这是因为请求的最后一个块必须哈希更多的 token,并且不太可能被其他请求重用。因此,它应该首先被驱逐。
驱逐 (LRU)¶
当空闲队列的头部块(最近最少使用的块)被缓存时,我们必须驱逐该块以防止其被其他请求使用。具体来说,驱逐涉及以下步骤
- 从空闲队列的头部弹出该块。这是要被驱逐的 LRU 块。
- 从缓存块中移除块 ID。
- 移除块哈希。
示例¶
在此示例中,我们假设块大小为 4(每个块可以缓存 4 个 token),并且 KV 缓存管理器中总共有 10 个块。
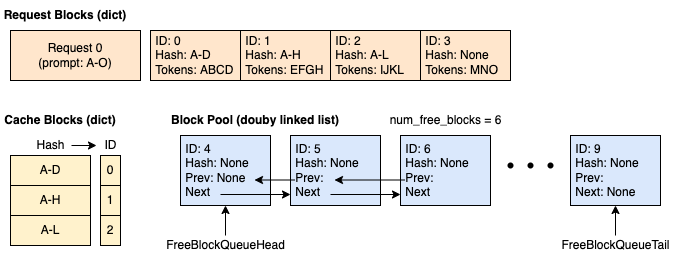
时间 1:缓存为空,新请求进入。 我们分配 4 个块。其中 3 个已满并被缓存。第四个块部分已满,包含 4 个 token 中的 3 个。
时间 3:请求 0 使块 3 变满并请求新块以继续解码。 我们缓存块 3 并分配块 4。
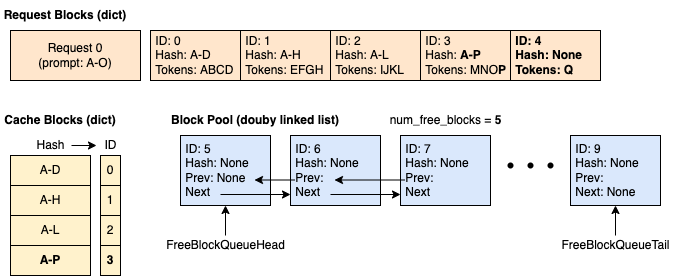
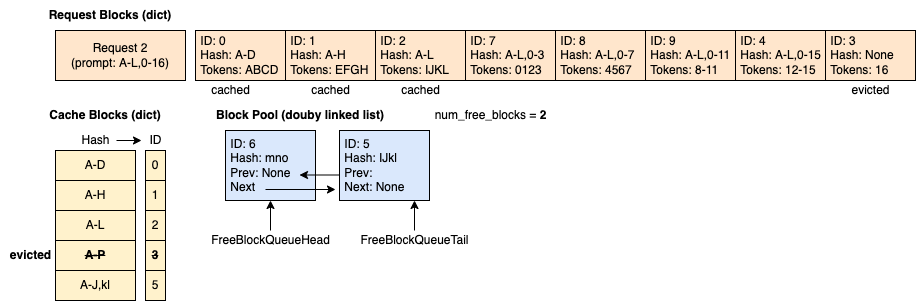
时间 4:请求 1 带着 14 个提示 token 进入,其中前 10 个 token 与请求 0 相同。 我们可以看到只有前 2 个块(8 个 token)命中了缓存,因为第 3 个块只匹配了 4 个 token 中的 2 个。
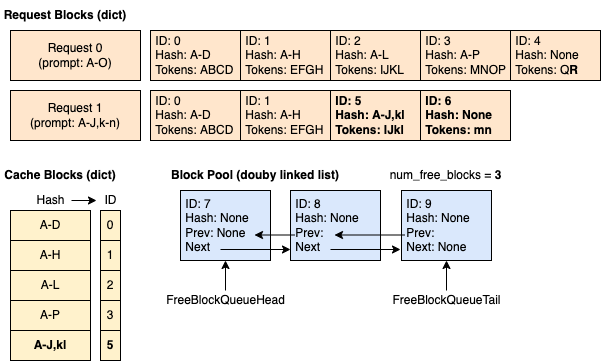
时间 5:请求 0 完成并释放。 块 2、3 和 4 以反向顺序添加到空闲队列(但块 2 和 3 仍然被缓存)。块 0 和 1 未添加到空闲队列,因为它们正被请求 1 使用。
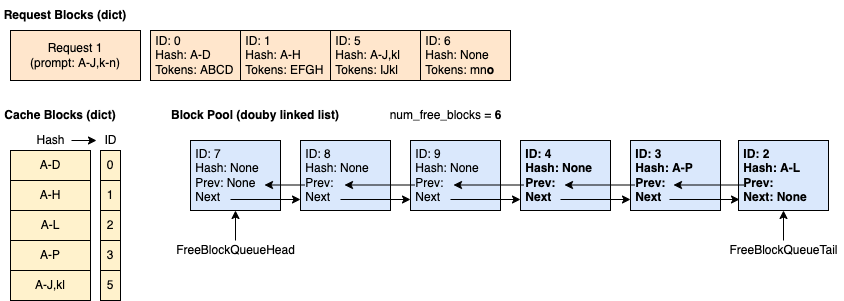
时间 6:请求 1 完成并释放。
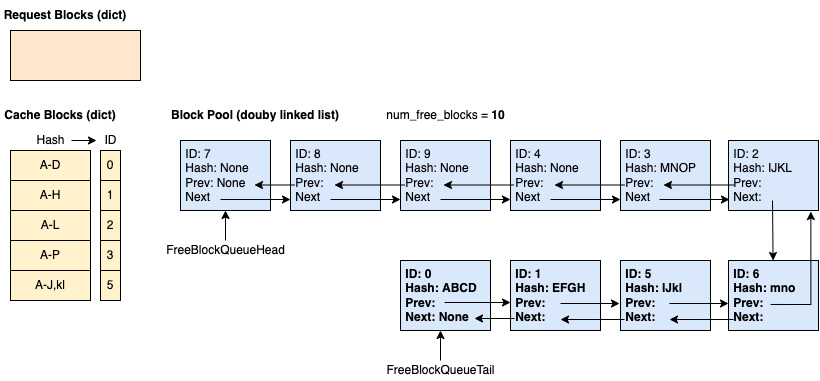
时间 7:请求 2 带着 29 个提示 token 进入,其中前 12 个 token 与请求 0 相同。 请注意,尽管空闲队列中的块顺序是 7 - 8 - 9 - 4 - 3 - 2 - 6 - 5 - 1 - 0,但缓存命中的块(即 0、1、2)在分配前被触碰并从队列中移除,因此空闲队列变为 7 - 8 - 9 - 4 - 3 - 6 - 5。结果,分配的块是 0(已缓存)、1(已缓存)、2(已缓存)、7、8、9、4、3(已驱逐)。