多节点测试#
多节点 CI 旨在测试非常大模型的分布式场景,例如:跨多节点的 disaggregated_prefill 多 DP 等。
工作原理#
下图展示了多节点 CI 机制的基本部署视图,它展示了 github action 如何与 lws(一种 Kubernetes CRD 资源)进行交互。
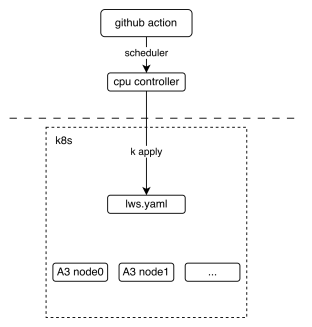
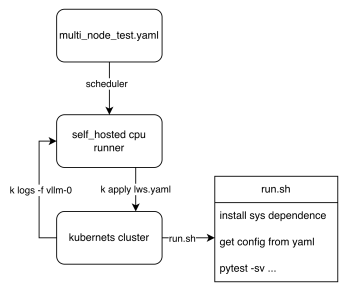
从工作流的角度来看,我们可以看到最终的测试脚本是如何执行的。关键在于这两个 lws.yaml 和 run.sh。前者定义了我们的 k8s 集群如何启动,后者定义了 pod 启动时的入口脚本。每个节点根据 LWS_WORKER_INDEX 环境变量执行不同的逻辑,从而使多个节点能够组成一个分布式集群来执行任务。
如何贡献#
上传自定义权重
如果您需要自定义权重,例如,您为 DeepSeek-V3 量化了一个 w8a8 权重,并且希望您的权重能在 CI 上运行,欢迎将权重上传到 ModelScope 的 vllm-ascend 组织。如果您没有上传权限,请联系 @Potabk。
添加配置文件
如入口脚本 run.sh 所示,Kubernetes Pod 启动意味着遍历 目录 中的所有 *.yaml 文件,并根据不同的配置进行读取和执行。因此,我们所需要做的就是添加像 DeepSeek-V3.yaml 这样的“yaml 文件”。
假设您有 **2 个节点** 运行 1P1D 设置(1 个预填充器 + 1 个解码器)
您可以添加一个如下所示的配置文件
test_name: "test DeepSeek-V3 disaggregated_prefill" # the model being tested model: "vllm-ascend/DeepSeek-V3-W8A8" # how large the cluster is num_nodes: 2 npu_per_node: 16 # All env vars you need should add it here env_common: VLLM_USE_MODELSCOPE: true OMP_PROC_BIND: false OMP_NUM_THREADS: 100 HCCL_BUFFSIZE: 1024 SERVER_PORT: 8080 disaggregated_prefill: enabled: true # node index(a list) which meet all the conditions: # - prefiller # - no headless(have api server) prefiller_host_index: [0] # node index(a list) which meet all the conditions: # - decoder # - no headless(have api server) decoder_host_index: [1] # Add each node's vllm serve cli command just like you run locally deployment: - server_cmd: > vllm serve ... - server_cmd: > vllm serve ... benchmarks: perf: # fill with performance test kwargs acc: # fill with accuracy test kwargs
本地运行(选项)
步骤 1. 向配置文件添加 cluster_hosts
在每个集群主机上修改,命令如下:例如,在 DeepSeek-V3.yaml 的
num_nodes配置项之后,例如:cluster_hosts: ["xxx.xxx.xxx.188", "xxx.xxx.xxx.212"]步骤 2. 安装开发环境
在每个集群主机上安装 vllm-ascend 开发包。
cd /vllm-workspace/vllm-ascend python3 -m pip install -r requirements-dev.txt
在集群主机中的第一个主机(leader 节点)上安装 AISBench。
export AIS_BENCH_TAG="v3.0-20250930-master" export AIS_BENCH_URL="https://gitee.com/aisbench/benchmark.git" git clone -b ${AIS_BENCH_TAG} --depth 1 ${AIS_BENCH_URL} /vllm-workspace/vllm-ascend/benchmark cd /vllm-workspace/vllm-ascend/benchmark pip install -e . -r requirements/api.txt -r requirements/extra.txt
步骤 3. 本地运行测试
导出环境变量
在 leader 主机上(第一个节点 xxx.xxx.xxx.188)
export LWS_WORKER_INDEX=0 export WORKSPACE=/vllm-workspace export CONFIG_YAML_PATH=DeepSeek-V3.yaml export FAIL_TAG=FAIL_TAG
在 slave 主机上(其他节点,例如 xxx.xxx.xxx.212)
export LWS_WORKER_INDEX=1 export WORKSPACE=/vllm-workspace export CONFIG_YAML_PATH=DeepSeek-V3.yaml export FAIL_TAG=FAIL_TAG
LWS_WORKER_INDEX是此节点在cluster_hosts中的索引。索引为 0 的节点是 leader。slave 节点的索引值范围是 [1, num_nodes-1]。运行 vllm 服务实例
在每个集群主机上复制并运行 run.sh,以启动 vllm,命令如下。
cp /vllm-workspace/vllm-ascend/tests/e2e/nightly/multi_node/scripts/run.sh /vllm-workspace/ cd /vllm-workspace/ bash -x run.sh
将该用例添加到当前的 nightly 工作流中,多节点测试工作流定义在 vllm_ascend_test_nightly_a2/a3.yaml 中。
multi-node-tests: needs: single-node-tests if: always() && (github.event_name == 'schedule' || github.event_name == 'workflow_dispatch') strategy: fail-fast: false max-parallel: 1 matrix: test_config: - name: multi-node-deepseek-pd config_file_path: tests/e2e/nightly/multi_node/config/models/DeepSeek-V3.yaml size: 2 - name: multi-node-qwen3-dp config_file_path: tests/e2e/nightly/multi_node/config/models/Qwen3-235B-A22B.yaml size: 2 - name: multi-node-dpsk-4node-pd config_file_path: tests/e2e/nightly/multi_node/config/models/DeepSeek-R1-W8A8.yaml size: 4 uses: ./.github/workflows/_e2e_nightly_multi_node.yaml with: soc_version: a3 image: m.daocloud.io/quay.io/ascend/cann:8.3.rc2-a3-ubuntu22.04-py3.11 replicas: 1 size: ${{ matrix.test_config.size }} config_file_path: ${{ matrix.test_config.config_file_path }}
上面的 matrix 定义了添加多机用例所需的所有参数。值得关注的参数(如果正在添加新用例)是 size 和 yaml 配置文件路径。前者定义了用例所需的节点数,后者定义了您在步骤 2 中完成的配置文件的路径。