Disaggregated-prefill#
为什么使用 disaggregated-prefill?#
此功能旨在优化大规模推理任务中的每输出 token 时间 (TPOT) 和首次 token 时间 (TTFT)。其动机是双重的:
调整 P 和 D 节点的并行策略和实例数量
使用 disaggregated-prefill 策略,此功能允许系统灵活地调整 P (Prefiller) 和 D (Decoder) 节点的并行化策略(例如,数据并行 (dp)、张量并行 (tp) 和专家并行 (ep))以及实例数量。这可以更好地进行系统性能调优,尤其是在 **TTFT** 和 **TPOT** 方面。优化 TPOT
在没有 disaggregated-prefill 策略的情况下,预填充任务会被插入到解码过程中,这会导致效率低下和延迟。disaggregated-prefill 通过允许更好地控制系统的 **TPOT** 来解决这个问题。通过有效管理分块的预填充任务,系统避免了确定最佳分块大小的挑战,并提供了对生成输出 token 所需时间的更可靠控制。
用法#
vLLM Ascend 目前支持两种类型的连接器来处理 KV 缓存管理。
MooncakeConnector:D 节点从 P 节点拉取 KV 缓存。
MooncakeLayerwiseConnector:P 节点以分层的方式将 KV 缓存推送到 D 节点。
有关分步部署和配置,请参阅以下指南:
https://vllm-ascend.readthedocs.io/en/latest/tutorials/pd_disaggregation_mooncake_multi_node.html
工作原理#
1. 设计方法#
在 disaggregated-prefill 模式下,全局代理接收外部请求,将预填充转发给 P 节点,将解码转发给 D 节点;KV 缓存(键值缓存)通过点对点 (P2P) 通信在 P 和 D 节点之间交换。
2. 实现设计#
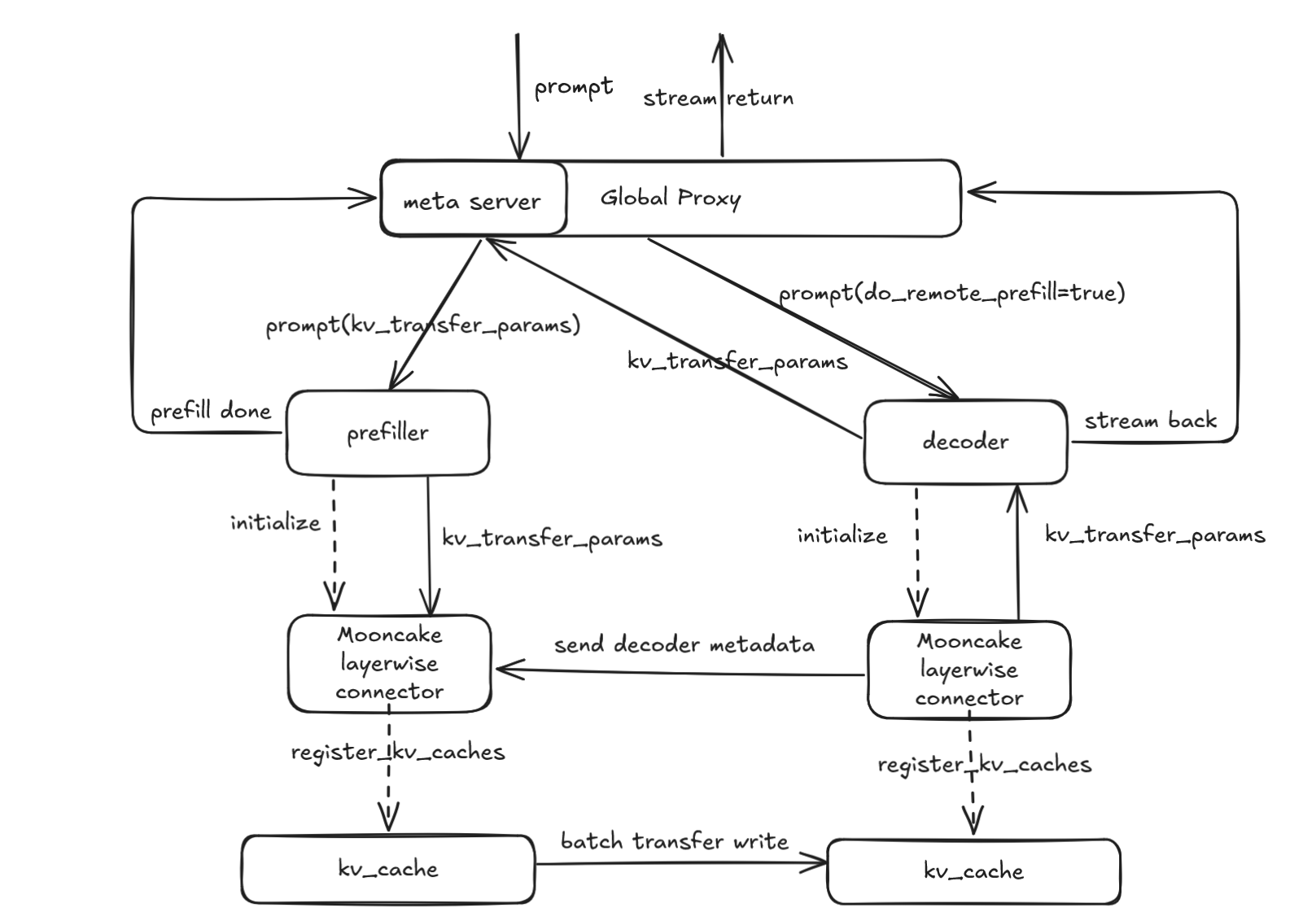
我们的设计图如下所示,分别说明了拉取和推送方案。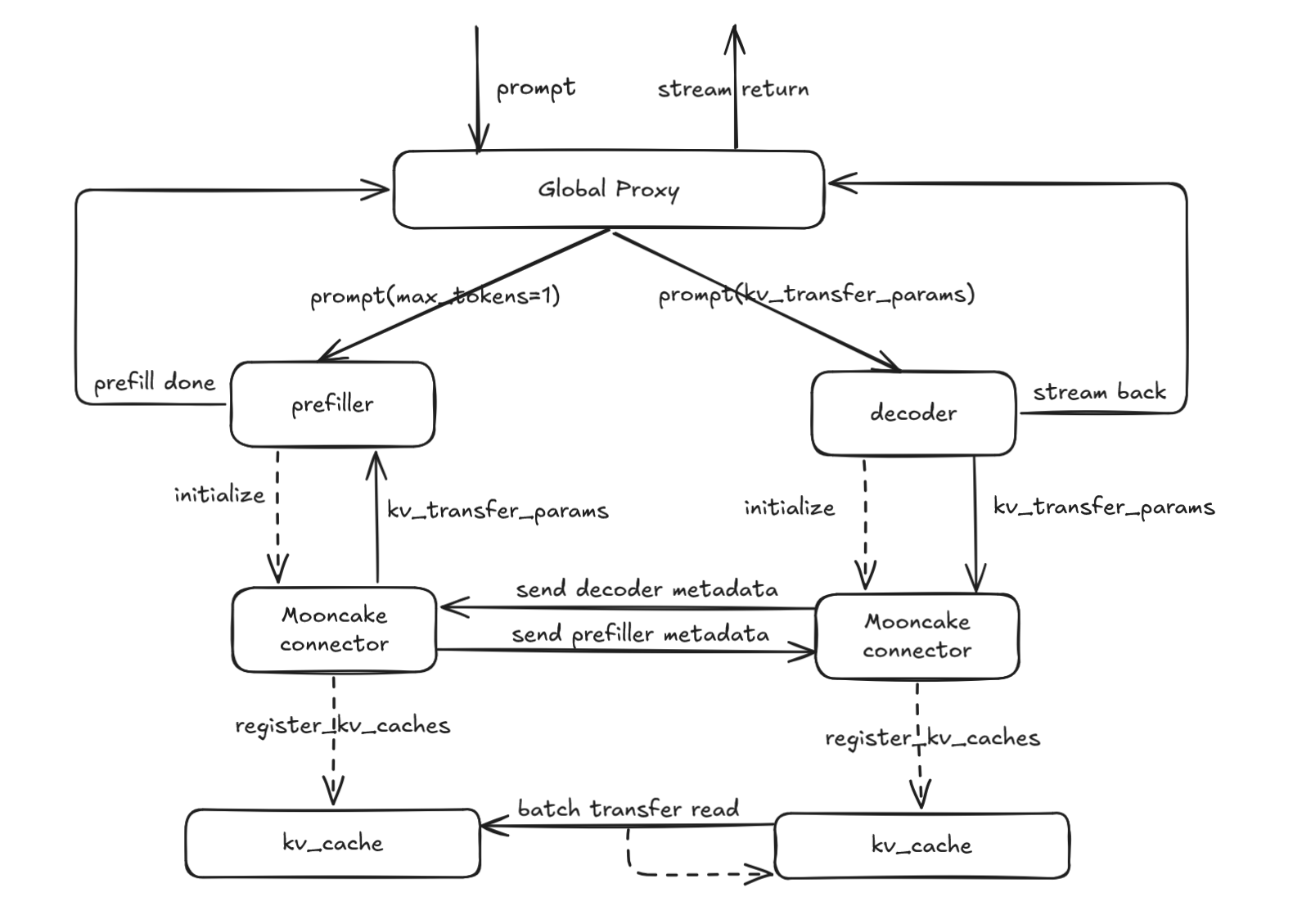
Mooncake Connector:#
请求发送到 Proxy 的
_handle_completions端点。Proxy 调用
select_prefiller选择一个 P 节点,并转发请求,将kv_transfer_params配置为do_remote_decode=True,max_tokens=1, 和min_tokens=1。在 P 节点的调度器完成预填充后,
update_from_output调用调度连接器的request_finished来延迟 KV 缓存释放,构造kv_transfer_params,将其设置为do_remote_prefill=True,然后返回到 Proxy。Proxy 调用
select_decoder选择一个 D 节点并转发请求。在 D 节点上,调度器将请求标记为
RequestStatus.WAITING_FOR_REMOTE_KVS,预分配 KV 缓存,调用kv_connector_no_forward来拉取远程 KV 缓存,然后通知 P 节点释放 KV 缓存并继续解码以返回结果。
Mooncake Layerwise Connector:#
请求发送到 Proxy 的
_handle_completions端点。Proxy 调用
select_decoder选择一个 D 节点并转发请求,将kv_transfer_params配置为do_remote_prefill=True并设置metaserver端点。在 D 节点上,调度器使用
kv_transfer_params将请求标记为RequestStatus.WAITING_FOR_REMOTE_KVS,预分配 KV 缓存,然后调用kv_connector_no_forward向 metaserver 发送请求并等待 KV 缓存传输完成。Proxy 的
metaserver端点接收请求,调用select_prefiller选择一个 P 节点,并转发请求,将kv_transfer_params设置为do_remote_decode=True,max_tokens=1, 和min_tokens=1。在处理过程中,P 节点的调度器逐层推送 KV 缓存;当所有层推送完成后,它释放请求并通知 D 节点开始解码。
D 节点执行解码并返回结果。
3. 接口设计#
以 MooncakeConnector 为例,系统组织为三个主要类:
MooncakeConnector:提供核心接口的基类。
MooncakeConnectorScheduler:用于在引擎核心内调度连接器的接口,负责管理 KV 缓存传输需求和完成。
MooncakeConnectorWorker:用于管理工作进程中 KV 缓存注册和传输的接口。
4. 规格设计#
此功能灵活且支持多种配置,包括使用 MLA 和 GQA 模型的设置。它兼容 A2 和 A3 硬件配置,并支持涉及多个 P 和 D 节点之间均等和非均等 TP 设置的场景。
功能 |
状态 |
|---|---|
A2 |
🟢 可用 |
A3 |
🟢 可用 |
均等 TP 配置 |
🟢 可用 |
非均等 TP 配置 |
🟢 可用 |
MLA |
🟢 可用 |
GQA |
🟢 可用 |
🟢 功能性:完全可用,正在持续优化。
🔵 实验性:实验性支持,接口和功能可能会更改。
🚧 进行中:正在积极开发中,即将支持。
🟡 已规划:计划未来实现(部分可能有开放的 PR/RFC)。
🔴 无计划/已弃用:vLLM 无计划或已弃用。
DFX 分析#
1. 配置参数验证#
通过检查 kv_connector 类型是否受支持以及 kv_connector_module_path 是否存在且可加载来验证 KV 传输配置。在传输失败时,发出清晰的错误日志以供诊断。
2. 端口冲突检测#
启动前,通过尝试绑定来执行已配置端口(例如,rpc_port, metrics_port, http_port/metaserver)的端口使用情况检查。如果端口已被占用,则快速失败并记录错误。
3. PD 比例验证#
在非对称 PD 场景下,验证 P 到 D 的 tp 比例是否符合预期和调度约束,以确保正确可靠的运行。
局限性#
不支持异构 P 和 D 节点,例如,在 A2 上运行 P 节点而在 A3 上运行 D 节点。
在非对称 TP 配置中,仅支持 P 节点具有比 D 节点更高的 TP 度且 P TP 计数是 D TP 计数的整数倍的情况(即 P_tp > D_tp 且 P_tp % D_tp = 0)。